Nun die erste Programmaktualisierung auf Grund unserer Aktivitäten hier: Das Modul LIN (Lineage) von webtrees zeigte nicht alle Informationen aus der Testdatei korrekt an. Der Programmierer hat das aber schnell korrigiert. Hier nun die zugehörige Darstellung unserer Testfamilie, wie sie im nächsten Release des Moduls zu sehen sein wird.
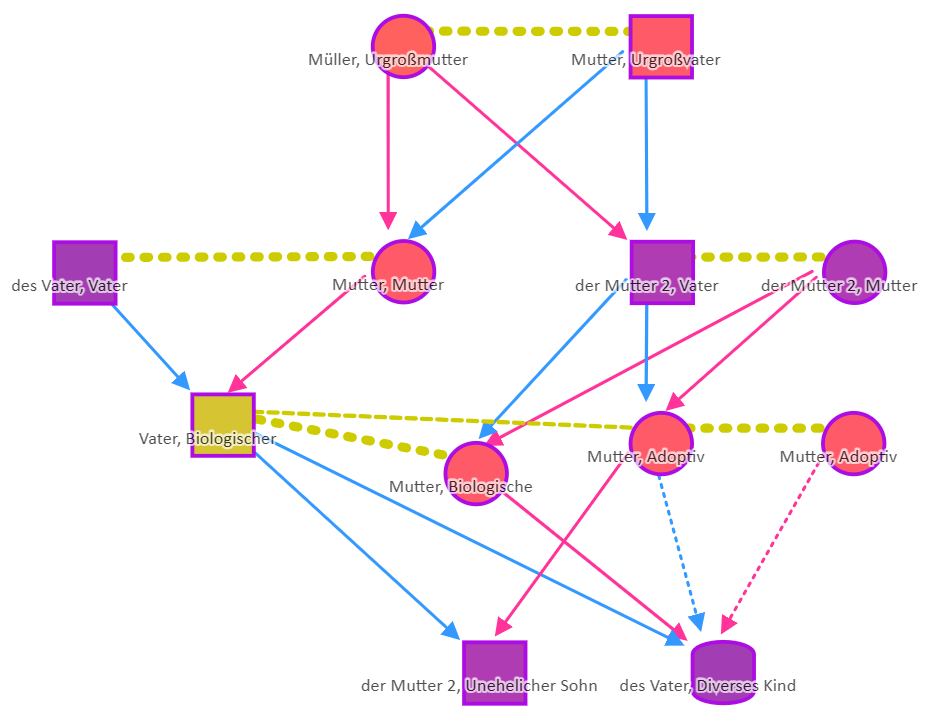
Als „Programmierer“ möchte ich mich auch selbst äußern … ich ziehe übrigens den Begriff „Entwickler“ vor …
Wer dieses Modul für solche Situationen nutzen möchte, muss in Kauf nehmen, dass die Erst-Ansicht etwas unübersichtlicher ist:
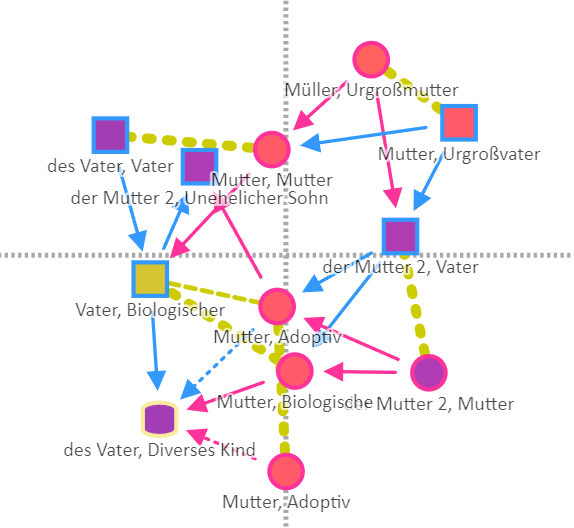
Die von Hermann dargebotene Ansicht ergibt sich nach entsprechendem Klicken und Ziehen der Personen-Icons. Insofern ist also persönlicher Aufbereitungsaufwand zu leisten. Hat andererseits den Vorteil, dass die Endansicht maximal auf die jeweils gewünschte Aussage hin optimiert werden kann.
Direkt ausdrucken kann man die Ansicht nicht, es gibt eine Export-Option als „freies SVG“ in der Form, dass eine unabhängige HTML-Datei erzeugt wird, welche dann nicht mehr reaktiv ist. Man kann darin allerdings noch nach Belieben zoomen und verschieben. Die könnte um eine selektive Druck-Option ergänzt werden.
Da hier diverse kompetente Teilnehmer engagiert sind, bitte ich um Einschätzungen für diese Frage:
huhwt-LIN ist eine Personen-orientierte Darstellung. Mit huhwt-TAM gibt es eine alternative Familien-orientierte Darstellung. Hier nun stoße ich auf eine Art „inverses Implex“-Problem: Durch die Adoption müsste das „des Vater, Diverses Kind“ in 2 Familien-Kreisen dargestellt werden. Hätte diese Person Nachkommen, müssten diese Zweige dann ebenfalls mehrfach auftauchen … Tatsächlich ergibt sich das Problem in dieser Form gar nicht, da anders als bei den im Thread diskutierten Programmen und Aufbereitungen die Objekte selbst die Informationsträger sind, es ist ein hochgradig dynamisches System und die Knoten/Icons und Verbindungen sind aktive Elemente. Weitere Beziehungen werden immer nur von dem jeweiligen Objekt aus aufgebaut. Zur Zeit schlage ich mich mit dem Problem herum, dass die Person „des Vater, Diverses Kind“ eben nur in einem Familien-Kreis auftaucht, nämlich die Adoptiv-Beziehung - der Kreis der biologischen Familie ist leer. Das ist sinnvoll, denn es ist die im zeitlichen Verlauf letzte relevante Zuordnung und entspricht der biografischen Entwicklung.
Meine aktuelle Präferenz ist, dass ich versuchen werde, im „Biologischen-Familien-Kreis“ eine Art „Schatten-Item“ zu implementieren, von dem dann eventuelle weitere Beziehungen eben nicht ausgehen können.
Das wäre im Gegenzug auch das für mich sinnvolle Vorgehen beim „richtigen“ Implex: Ausgebaut wird die Vorfahren-Linie von der Beziehung aus, welche im zeitlichen Ablauf das früheste Auftreten darstellt. Ist eine solche Person auch in anderen Beziehungen präsent, wird dort ein „Schatten-Item“ mit Verweis/Verlinkung auf den „richtigen“ Ankerpunkt installiert.
Ich bitte um Kommentare und Einschätzungen.
PS: Die Module huhwt-wtlin und huhwt-wttam sind nachgeordnete Module zu huhwt-cce, alles bei GitHub zu finden … huhwt bei GitHub. CCE [„Clippings Cart Enhanced“} ist der erweiterte webtrees-Sammelkorb, in dem man recht gezielt Teilmengen der Personen im Stammbaum auf diversen Wegen abgrenzen kann.
1 „Gefällt mir“
Wäre das einen Parameter in den Moduleinstellungen wert, um zwischen biografischer oder genealogischer Abstammung zu differenzieren?
Viele Grüße
Peter (Schulz)
Sorry! In Zeiten in denen schon KIs programmieren, sollte ich die Bezeichnung treffender wählen.
Erst dachte ich, dass das das ist, was andere als „Nachfahren-Implex“ bezeichnen. Aber es ist wohl ein neues Problem. Das diverse Kind gehört zu zwei Familien, seiner biologischen Familie und zu seiner Adoptivfamilie. Wenn das diverse Kind heiratet und selber Kinder bekommt, setzt sich das entsprechend fort. Wahrscheinlich würden manche Programme, dann alle diese Nachkommen doppelt aufführen, wenn sie es gut machen, wenigstens mit entsprechenden Querverweisen. Schöner wäre es natürlich ohne Dopplungen der Personen.
Ich habe die Testdatei mal in TAM dargestellt und etwas sortiert, so dass man das von Dir geschilderte Problem sehen kann.
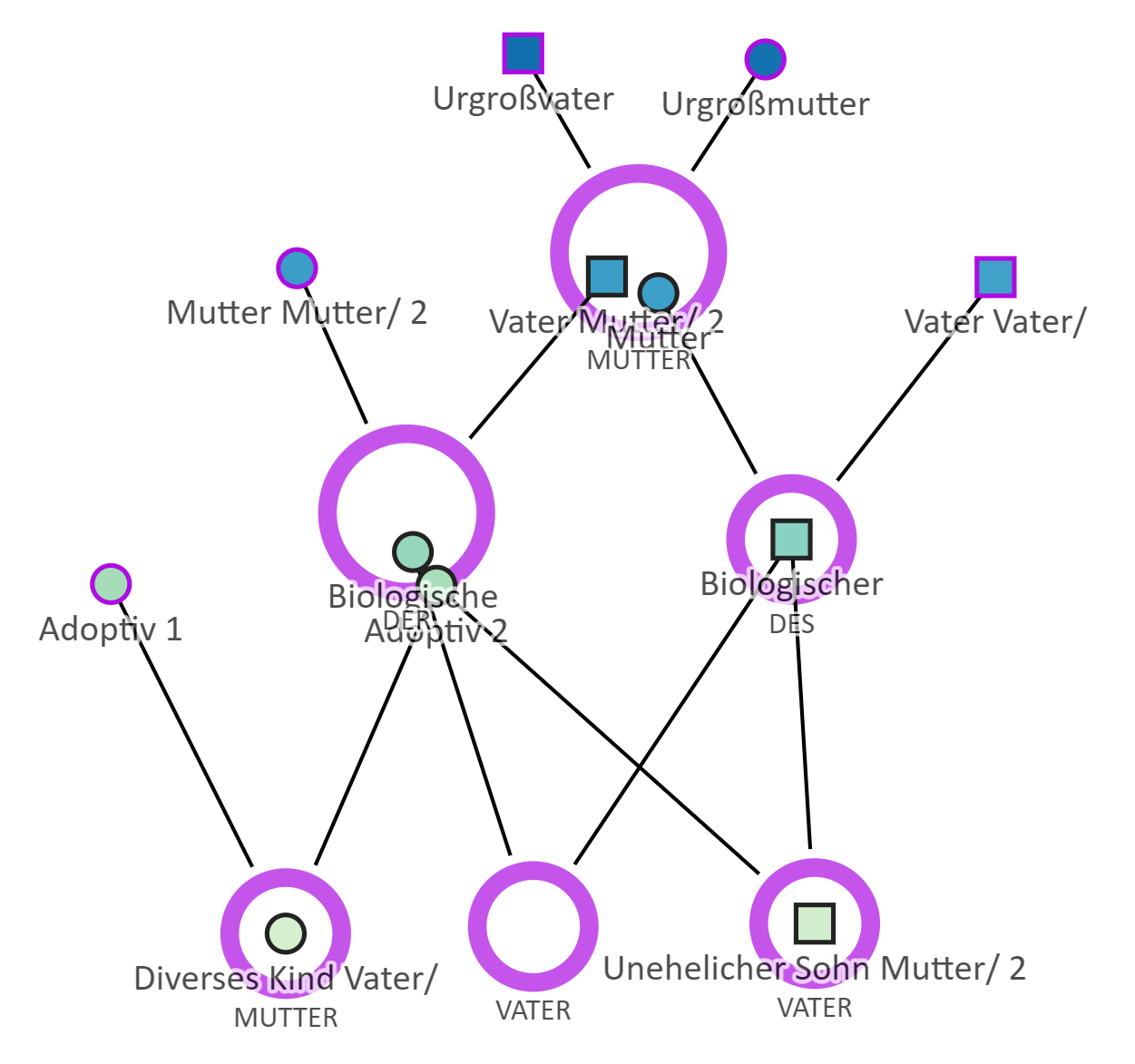
In den leeren Kreis ganz unten in der Mitte gehört eigentlich noch einmal das diverse Kind, in diesem Fall als Bestandteil der biologischen Familie. Ein Weg wäre tatsächlich das Anlegen eines Schatten-Items in dieser Familie mit einer neuen Kategorie von Link zur identischen Person „diverses Kind in der Adoptionsfamilie“. Wahrscheinlich eine gute Lösung. In der GEDCOM haben die beiden Familien „Biologie“ und „Adoption“ eine Reihenfolge, die bedeutet, dass die zuerst aufgeführte Familie die wichtigere ist. Das sollte also dazu dienen zu entscheiden in welcher Familie das Symbol für das Kind steht und in welcher Familie das Schatten-Item steht (also nicht die zeitliche Reihenfolge entscheidet, sondern der Wille des Nutzers indem er die Familien entsprechend sortiert, denn mal mag der Fokus auf der biologischen Familie liegen und ein anders Mal ist diese gegenüber der Adoptivfamilie völlig unbedeutend).
Ich selber bin in der Schule mit Mengenlehre groß geworden, so dass mir noch eine weitere Idee kam. Wie wäre es wenn man die beiden lila Familienkreise ganz unten links und in der Mitte übereinander nagelt und in die Schnittmenge der beiden Kreise das diverse Kind legt? Das ist schwieriger zu programmieren aber intuitiv verständlich und man braucht kein Schatten-Item und keine neue Link-Kategorie. In etwa so:
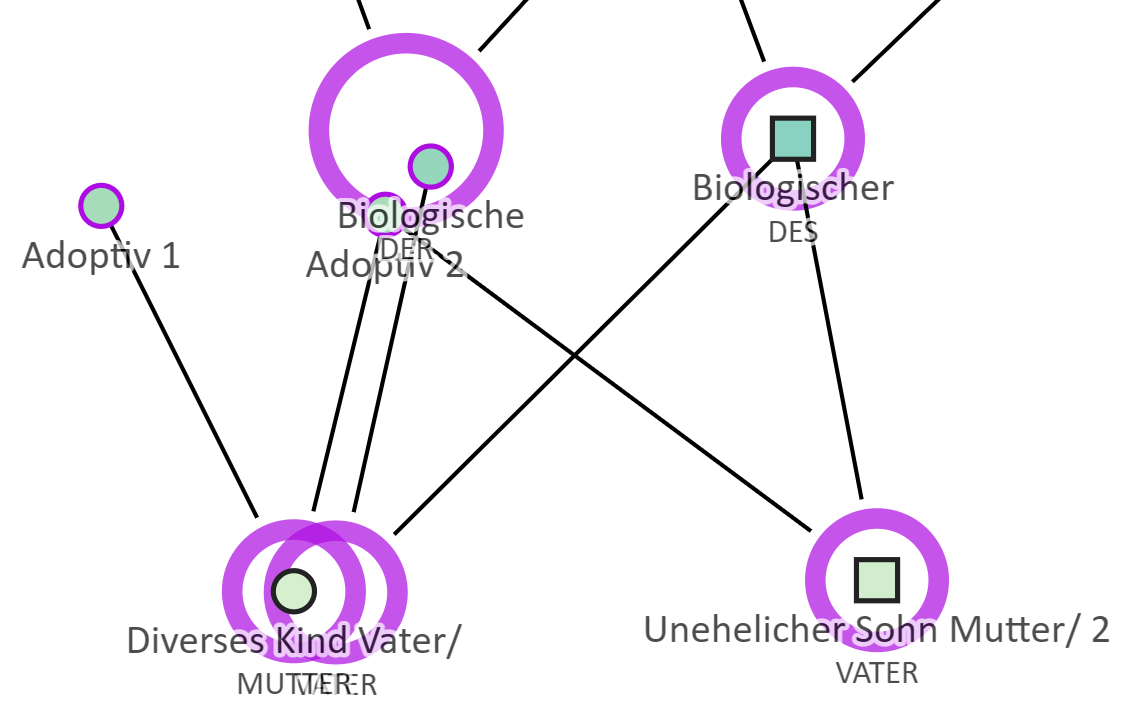
Wäre eine Möglichkeit, aber das würde dann ja immer die eine gegen die andere Familienart bevorzugen und das auch noch in allen Stammbäumen einer Installation. Aber in meinem Stammbaum will ich vielleicht einmal die biologische und ein anderes Mal die Adoptivfamilie bevorzugen. Daher würde ich es - wie oben geschrieben - bevorzugen, dass die Familienreihenfolge, die durch den Nutzer festgelegt worden ist, bei der Darstellung entscheidet.
PS: es gibt natürlich nicht nur zwei Familienarten. Es gibt auch noch die Pflegefamilie und im Islam die Milchmutter-Familie (Rada). Die Pflegefamilie ist Bestandteil des GEDCOM-Standards, die Rada-Familie wird von webtrees zusätzlich unterstützt. Eine Person kann also in etlichen Familien zu Hause sein, nicht nur in zwei. Und da ist Leihmutterschaft und ähnliches noch gar nicht berücksichtigt. ![]()
Über @Andreas_Sichelstiel erreichte mich die Nachricht, dass er auf eine weitere Dimension angesprochen worden ist. Andreas hat mich gebeten darüber hier zu berichten:
Wir haben hier bisher über genetische Familien (Ahnenforschung) und soziale Familien (Familienforschung) gesprochen, konkret erst einmal die Adoptionsfamilie, aber eben auch die Pflegefamilie (das ist alles in GEDCOM abgedeckt) oder noch weitere Familientypen in anderen Kulturen (die vielleicht in einer nächsten Version des GEDCOM-Standards auftauchen werden). Aber es gibt in GEDCOM noch weitere Beziehungen zwischen Personen, etwa zu Trauzeugen oder Taufpaten, wie man sie manchmal auch in Kirchenbüchern dokumentiert findet und die durchaus auch mal helfen können einen toten Punkt in der Ahnenforschung zu überwinden oder unklare Zusammenhänge aufzuklären. Gibt es Genealogieprogramme, die solche Beziehungen visualisieren können? Erfassen können das hoffentlich die meisten, aber grafisch anzeigen?
Und es gibt ja noch die Möglichkeit weitere Beziehungen (ASSO) in einem Stammbaum zu definieren, etwa die Beziehungen
- Arbeitnehmer - Chef
- Mieter - Vermieter
- Zwilling - Zwilling
- Drilling - Drilling - Drilling
- Stipendiaten der Hortich.Stiftung
- Mitglieder im CompGen-Verein
- Mitglieder des württembergischen Gebirgsbataillons
Gibt es auch noch Genealogieprogramme, die solche sozialen Netze visualisieren können? Mit LIN in webtrees wäre das sicher prinzipiell lösbar. Aber es gibt auch weitere Programme, die hier nützlich sein könnten, zum Beispiel
- socnetv.org
- gephi.org
- Graph-Datenbanken wie neo4j
Meist erfordern solche Tools eine Liste von Knoten und Kanten mit Attributen als Eingabe und dann produzieren sie daraus eine grafische Darstellung. Denkbar wäre es also, dass ein Genealogieprogramm eine solche Liste intern aus den Daten im Stammbaum erzeugt und über einen Webservice diese Informationen in ein Visualisierungstool zur Darstellung schickt. Ist das machbar? Wer machts?
Nachtrag:
Also wenn sich jemand hier dafür interessieren sollte, dann erstelle ich wieder eine kleine Testdatei mit sozialen Beziehungen. Was soll vorkommen? Neben Taufpaten und Trauzeugen fände ich den Anwendungsfall Stipendiaten der Hortich-Stiftung am attraktivsten. Was meinst Du @Silvia_Diessner? Ich bin sicher, dass ChatGPT aus so einer neuen GEDCOM-Testdatei wieder in Null-Komma-Nix eine Grafik zaubern kann.
1 „Gefällt mir“
[quote=„Hermann_Hartenthaler, post:115, topic:822464“]
In der GEDCOM haben die beiden Familien „Biologie“ und „Adoption“ eine Reihenfolge, die bedeutet, dass die zuerst aufgeführte Familie die wichtigere ist.
[/quote]
Man sollte frei wählen können, welche die „wichtigere“ Verbindung ist bzw. welche Verbindung dargestellt werden soll. So habe ich in meinem Stammbaum z.B. ein Adoptivkind, das auf keinen Fall mit den biologischen Eltern in Verbindung gebracht werden möchte. In dem Fall wäre dann natürlich „Adoption“ die darzustellende Verbindung.
Ich bin dabei. Sag mir wie groß die Testdatei sein soll, und ich schicke sie Dir.
Ich denke schon länger darüber nach, wie ich es grafisch darstellen kann, welcher Stipendiat zu welchem Stifter gehört. Für jeden Stifter eine Farbe geht nicht, da ein Stipendiat von bis zu fünf verschiedenen Stiftern abstammt (Beispiel)
In Webtrees sieht das derzeit so aus:

1 „Gefällt mir“
Danke für diesen wichtigen Punkt und das plausible Beispiel, @Ralf.S !
Bei einer graduellen Wichtung würde ich das über die Reihenfolge der Familien lösen, zu der eine Person gehört. Kann man in allen Programmen die Reihenfolge der Familien frei wählen? Bleibt die Reihenfolge bei Import/Export immer erhalten? Diese Funktion ist dann wichtig, wenn in einem Diagramm grundsätzlich nur eine Familie dargestellt werden kann, etwa bei einem Fächerdiagramm.
Das würde ich immer über die Einstellung der Vertraulichkeit (GEDCOM Kennzeichen RESN) lösen. Je nach Berechtigung des auswertenden Nutzers bekommt man dann nur die Adoptionsfamilie zu sehen (Standard) oder alle Familien (Administrator). Ich weiß aber nicht welche Programme außer webtrees das unterstützen, denn dazu muss das Programm auch ein Rollenkonzept anbieten. Der GEDCOM-Standard gibt es her.
Moin,
ist das Chatgpt 3.5 oder 4?
Jörn (Knabbe)
Ich habe ChatGPT 4 verwendet. Die kostenlose Version 3.5 kann auch mit GEDCOM umgehen, kann aber wahrscheinlich kein Diagramm zeichnen. Eine Biografie oder Analyse der GEDCOM-Daten geht aber, wenn die Datei nicht zu groß ist (maximal 3 Generationen). Dazu gab es umfangreiche Diskussionen hier auf Discourse in der Kategorie KI. Da findest Du mehr. Das Umfeld ist aber so schnelllebig, dass ich nicht sagen kann, mit welchen anderen Zugangsarten oder KIs das im GenWiki gezeigte Beispiel auch nachvollziehbar ist.
Danke für die Information.
Jörn (Knabbe)
Erinnerungen zu bemühen und die Segnungen/Traumata des Mengenlehre-orientierten Einstiegs in das mathematische Denken heraufzubeschwören - nun ja, das ist vielleicht eine sinnvolle Lesart der Situation, zumal hier auch noch andere verbindende Elemente gegeben sind.
Es ist aber auch ein anderer seinerzeit oft bemühter Gedanke relevant: Die „normative Kraft des Faktischen“.
Fakt ist in diesem Fall, dass die Darstellung über eine Force-Simulation erzeugt wird. Im Grunde sagt das aus, dass man am Anfang einen wirren Haufen Knoten und Verbindungen dazwischen erzeugt, und damit sich daraus ein einigermaßen überschaubares Bild ergibt, darauf in einer Vielzahl von Iterationen einen ganzen Strauß von überwiegend abstoßenden Kräften verrechnet. Der zentrale Gedanke dabei ist, dass es am Ende möglichst keine Überlagerung von Knoten mehr gibt. Die Familenkreise sind Knoten, Konten sollen sich nicht überlagern … den zugrundeliegenden Algorithmus kann ich nicht so verbiegen, dass eine Schnittmengendarstellung wie angedacht machbar wäre.
Verstehe ich. Schade dass es die Mengenlehre nicht richten kann.
In Gramps gibt es ein Beziehungsdiagramm mit dem ich mal meinen Stammbaum visualisiert habe. Im Original pdf-Dokument kann ich auf 6400% vergrößern und kann so gerade noch alles lesen, aber es ist schon sehr unübersichtlich. Ziemlich weit unten, etwas rechts von der Mitte habe ich mich in roter Farbe markiert (man kann es kaum erkennen). Es ist schon interessant mal so von ganz oben auf den eigenen Stammbaum zu sehen. Direkt über mir geht es ganz schön weit zurück. Anscheinend habe ich dann irgendwann mal etliche Linien der entferntesten Verwandten nach unten verfolgt, das sind die Zweige die vom oberen Bildrand herunterhängen, aber keine Verbindung in die Gegenwart gefunden haben. Und ich erkenne, dass ich anscheinend drei, vier Nebenverwandtschaftszweige recht umfangreich erforscht habe; mein Baum geht recht in die Breite und ist eher eine Heckenlandschaft als ein Baum.
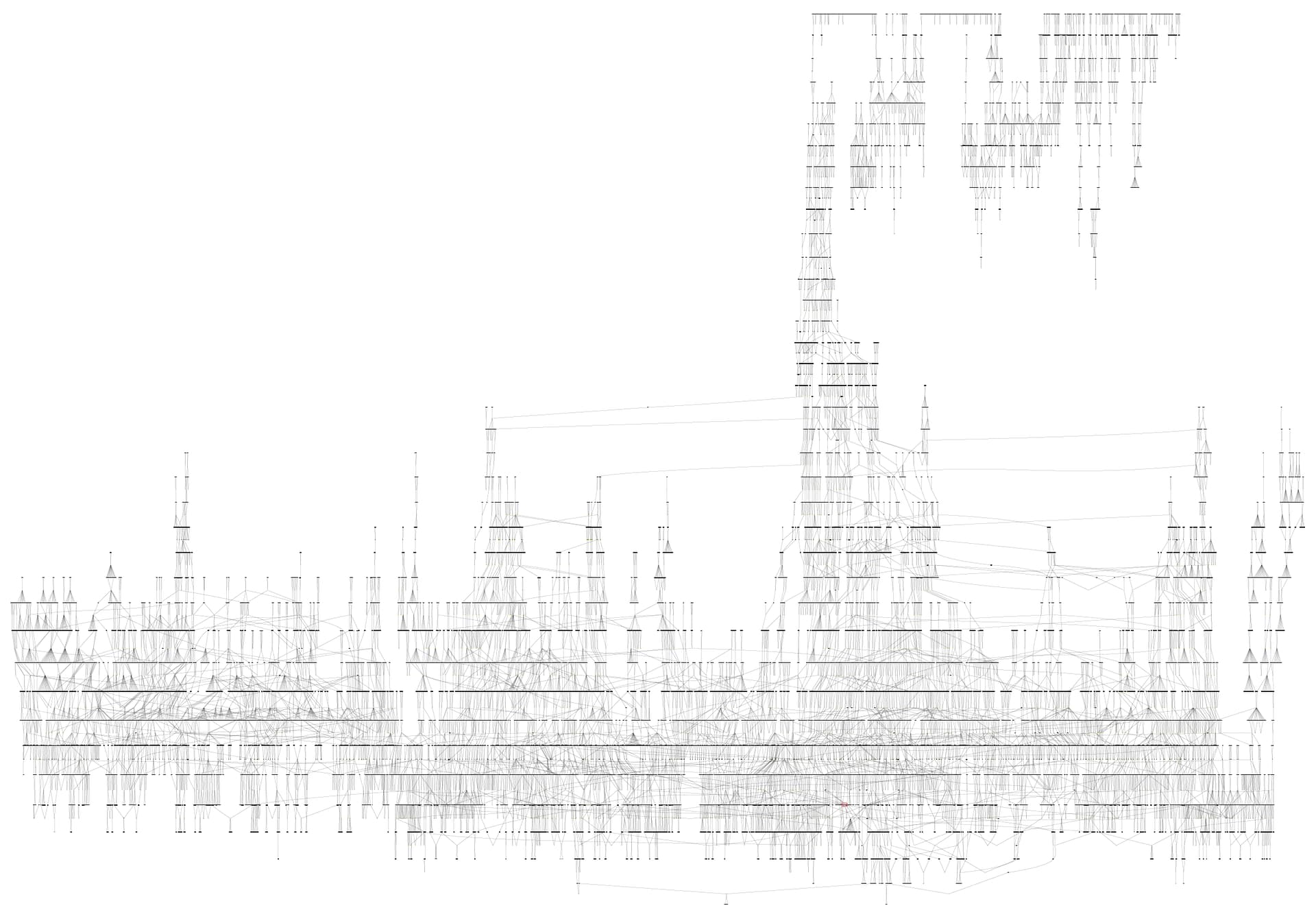
2 „Gefällt mir“
Guten Morgen Hermann,
diese Ansicht gefällt mir sehr gut und zeigt exemplarisch den Nutzen von ungewöhnlichen Ansichten. Freilich, um seiner Verwandtschaft bei einem Treffen die eigene Familie resp. die Daten die man von ihnen hat zu zeigen sind solche Ansichten komplett unbrauchbar.
Aber für eng definierte Fragestellungen um sich seinen Datenwust nach bestimmten Kriterien anzusehen sind sie wichtig. Je mehr Daten man hat desto eher werden diese „Spezialansichten“ interessant.
Grüße
Andreas
Hallo Hermann,
vielen Dank für das umfangreiche Werk.
Gratuliere.
Was ich aber erkennen kann, es handelt sich um eine Verwandtschafts-Darstellung.
… ein Stammbaum würde von einer Person ausgehend die Nachfahren darstellen.
Was ich sehr spannend finde: wie viele Personen werden auf dem Bild dargestellt?
Kann man überhaupt noch Daten und Namen erkennen?
Welches Papierformat hätte der Ausdruck?
Meine Erfahrungen, welche ich mit meinem Programm GenprofiStammbaum gesammelt habe: für mich mache ich nur einstellige Generationenanzahl. Diese Plots haben für mich noch einigermaßen Qualität der Inhalte.
Der Inhalt pro Person welche ich dazu erforderlich finde sind bei mir 10 Datenfelder (Personen-ID, Vorname, Nachname, Beruf, U-ID, Referenz-Code, Quelle, Alter, Geburtsdatum mit Ort und Todesdatum mit Ort). Im absoluten Notfall reduziere ich auf 6 Felder!
Nochmals vielen herzlichen Dank und schöne Grüße Heinz
Moin,
das halte ich persönlich aber für falsch. Hier geht es ja nicht darum, eine Verwandschaftsbeziehung verschiedener Personen aufzuzeigen. Wenn es um solche Dinge wie in der Auflistung unten geht - wäre man dann nicht besser bedient mit einer Liste auf alle Personen, die dieser Gruppe zugehören? Muß ich dafür ein Diagramm mit Linien und Boxen haben?
Jan Escholt
Sehe ich auch so. Am obigen Beispiel sieht man sofort, dass ich mehr Familien-Forschung als Ahnen-Forschung betreibe. Und die Unsinnigkeit des Wortes Stammbaum für meine Datenstruktur ist auch offensichtlich. Es wäre mal interessant zu sehen wie das aussieht, wenn jemand im wesentlichen nur Blutsverwandte, also ohne angeheiratete Zweige erforscht hat. Es wird wegen Ahnenimplex auch kein Baum sein, aber es müsste ganz anders aussehen als bei mir.
1 „Gefällt mir“
Da sprichst du mir aus der Seele, seit über 20 Jahren erforsche ich den Namen Sichelstiel. Egal, ob verwandt oder nicht, dazu kommt dann noch die Hofgeschichte.Die klassische Ahnenforschung fristet bei mir ein Nischendasein.
Bis zu den Großeltern meiner Großeltern habe ich das aber auch durchexerziert. Alles darüber wird mir zu abstrakt und verliert den Bezug für mich. Aber das ist ein ganz anderes Thema und muss hier nicht diskutiert werden.
Grüße
Andreas