was mache ich eigentlich, wenn ich mein Admin-Passwort verbummelt habe?
Bitte nicht antworten: neu installieren.
Ich bin gerade umgezogen und froh, dass scheinbar alles geklappt hat. Jedenfalls funktioniert die Verbindung zur Datenbank. Nur eben der Login klappt beim neuen Hoster nicht. Mit einer zweiten Installation bin ich auf eine neue Domain umgezogen, Startbildschirm sieht auch hier gut aus, aber Login?
Ich hoffe, dass die Zugangsdaten in einer php-Datei gespeichert sind, aber in welcher? Als Admin habe ich ja keinen Link „neue Zugangsdaten anfordern“ oder Passwort zurücksetzen o.ä.
Vielleicht könnte ich die php-Datei ersetzen, in der „Passwort vergessen“ steht. Allerdings weiß ich nicht, welche das ist.
Oder ich importiere nochmal komplett neu. Ich hatte nämlich das Phänomen, dass das FTP-Programm mehrmals gemeldet hat, dass die zu importierende Datei bereits vorhanden ist. Eigentlich ist das nicht möglich, oder? Ich habe in ein leeres Verzeichnis importiert. Wenn die vorhandene Datei gleich groß war, habe ich „überspringen“ gewählt, war die Zieldatei 0 Bytes groß, habe ich „überschreiben“ gewählt.
Eigentlich solltest Du bei einem manuellen Update per FTP immer „überschreiben“ auswählen. Denn.auch bei gleicher Dateigröße kann ein Komma, das durch einen Punkt ersetzt worden ist, eine signifikante Änderung sein.
Beim Drüberkopieren bleiben ggf. alte Dateien auf dem Server stehen, die es in der neuen Version nicht mehr gibt. Das ist normalerweise kein Problem, aber es kam vereinzelt doch zu komischen Effekten. Daher sollte zuvor der webtrees-Ordner vendor auf dem Server gelöscht werden.
Hallo Silvia,
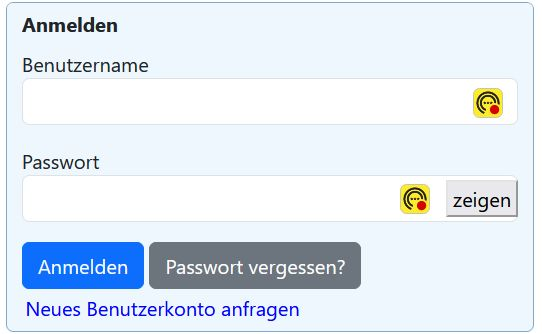
wenn Du - wie vorgeschlagen - eine neue Anfangsseite vorschaltest, dan hast Du da bei dem Logon-Block die Option „Passwort vergessen“ drin. Du brauchst dann nicht mit PHP-Dateien zu experimentieren.
Verstehe. Das kann aber nicht der Fehler bei meiner Installation sein. Ich ziehe zu einem neuen Hoster um. Beim alten Hoster habe ich das gesamte Webtrees-Verzeichnis per FTP runtergeladen und beim neuen Hoster dieselben Dateien, unverändert, in ein leeres Verzeichnis hochgeladen. Da sind keine alten Dateien vorhanden. Zwei verschiedene Versionen sind es auch nicht, nur Download und wieder Upload meiner vorhandenen Installation.
Ich lösche beim neuen Hoster nochmal komplett das Verzeichnis und werde alle Dateien überschreiben. Ich kann ja Screenshots machen, wo vermeintlich schon Dateien vorhanden sind.
Ich empfehle Dir nicht die von einem Hoster runtergeladene Version bei einem anderen Hoster wieder hochzuladen, sondern immer die aktuelle Original webtrees Version zu installieren.
Du hattest von von Überschreiben von Dateien gesprochen, das deckt sich nicht mit der Installation auf einem leeren Server. Irgendetwas passt da nicht zusammen.
Hast Du die Datenbank auch umkopiert? Bist Du genau so vorgegangen wie es in FAQ - move to a new server beschrieben ist?
Ich glaube, dass das Passwort für den Zugriff nicht in einer php-Datei auf dem Server gespeichert wird, sondern in der Datenbank, die auf dem Server für webtrees angelegt wurde. Die Datenbank ist ja auch wiederum durch ein Kennwort gesichert und verschlüsselt, Deine Anwendung (webtrees) greift mithilfe dieses Kennworts und eines Funktionsusers auf die Datenbank zu.
Ich habe leider keine Kenntnis, ob man das Kennwort hierüber auslesen könnte. Mit entsprechenden SQL-Kenntnissen wahrscheinlich schon. Bedingt aber, dass Du vor dem Wechsel Deines Hosters auch die Datenbank mittels eines Datenbank-Dumps kopiert hast (siehe auch Info in der offiziellen Anleitung, die Hermann geschickt hat). Die muss danach aber ebenso wieder eingebunden werden.
Wenn Du eine Neuinstallation von webtrees durchführst, wirst Du automatisch nach einem neuen Benutzer und Kennwort gefragt. Der Datenbank-Import könnte das u. U. dann aber überschreiben. Die Anleitung sagt leider nichts darüber aus. Das könnte der Knackpunkt bleiben.
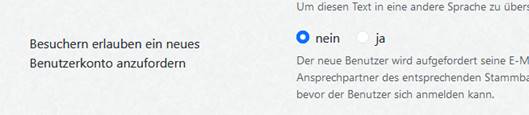
Auf meiner Webseite habe ich den Punkt „Neues Benutzerkonto anfragen“ übrigens ausgestellt, das ist also eine Einstellung in der Administration von Webtrees.
die gute Nachricht zuerst: bei einer von zwei Installation war der erneute Upload erfolgreich, ich kann mich einloggen.
Eine Neuinstallation wollte ich mir eben gerade ersparen. Jeder hat speziftische Einstellungen oder Module usw., die alle neu angepasst werden müssten.
Ich kann Dir versichern, dass ich die Daten in ein leeres Verzeichnis hochgeladen habe.
Die Meldung „Zieldatei existiert bereits“ kam bei folgenden Dateiein (bitte / durch \ ersetzen) in genau dieser Reihenfolge.
ja, den Gedanken hatte ich jetzt auch.
D.h., wenn die falsche Datenbank verknüpft wurde, kann der Login nicht funktionieren.
Ich setze die zweite Installation nochmal neu auf, vielleicht klappt es, ansonsten tatsächlich Neuinstallation.
Wenn Du nach der Neuinstallation die gesicherte Datenbank rüberkopierst, sind alle Einstellungen inkl Passwörtern wieder da, da diese ja in der Datenbank stehen. Wichtig ist aber, dass vor und nach dem Umzug genau die gleiche webtrees-Version installiert ist (derzeit 2.1.18), sonst passt es eventuell nicht.
Ich brauche bitte nochmal eine kleine Nachhilfe. Login hat jetzt funktioniert nachdem ich alles komplett gelöscht und neu hochgeladen habe. Aber mir fehlen ein paar Themen, auch mein Lieblingsthema, leider. Auf dem Server sind alle Dateien vorhanden, aber auf der Seite kann ich nur Clouds, minimal und Xenea auswählen.
Gibt’s einen Trick oder irgendwelche Einstellungen, wie ich das wieder hinbekomme?
Ich arbeite mit 1.7.18.
Wäre das jetzt nicht ein guter Zeitpunkt um auf 2.1.18 zu aktualisieren? Dann ist das Problem wahrscheinlich gelöst oder zumindest kann man Dir dann besser helfen.
trotzdem Danke. Alternativ könnte ich ja noch 1.7.20 ausprobieren. Da hat es aber mit der Stapelverarbeitung gehakt, deshalb habe ich jetzt erstmal meine alte Installation hochgeladen.
Ich lade den themes-Ordner nochmal neu hoch. Habe mir vor ein paar Tagen schon die „frische“ 1.7.18 runtergeladen.
Aber erstmal muss ich zusehen, dass die Basics laufen. Bin gerade fast vom Stuhl gekippt. Die Gedcom beim neuen Hoster war noch kleiner (also abgeschnitten) als beim alten. Hilfe. Noch dreimal probiert, jetzt ist sie 3 MB größer als die auf dem Server.
Hallo Hermann,
für mich nicht. Du kennst mein Thema „Forschungsaufgabe“ oder weiter gefasst: Abfragen.
Da ab V 2.0 die Möglichkeit fehlt, über die Erweiterte Suche in Kombination Forschungsaufgabe eigene Abfragen zu erstellen, wäre die 2.1 ein deutlicher Rückschritt in meiner täglichen Arbeit.
Die voreingestellten Berichte sind keine ausreichende Alternativen, zumal die Ausgabe in pdf oder html erfolgt.
Ich kann gar nicht glauben, dass es dafür wirklich keinen Bedarf gibt. Schau Dir andere Datenbankprogramme an: Access - der Nutzer kann beliebig viele selbst erstellte Abfragen anlegen. Oder Gramps - auch da kann man selbst Abfragen generieren und seine Daten nach immer neuen Aspekten filtern lassen. Gramps geht mit GrampsHub jetzt auch online, vergleichbar mit dem Modell von Peter. Die Entwicklung bleibt abzuwarten, aber es ist dann neben TNG ein weiteres mehrbenutzerfähiges Programm.
Stimmt, der Punkt war ja noch offen, hatte ich verdrängt. Hattest Du dazu in webtrees einen „issue“ eingestellt? Es sollte ja kein Hexenwerk sein die Suche nach ToDo-Einträgen wieder zuzulassen.
Nun, das geht hier natürlich auch. Ich vermute Deine Datenbank basiert auf MySQL. Da kann man per SQL-Abfrage so gut wie alles abfragen. Allerdings ist das eher verpönt, denn zum einen unterstützt webtrees etliche verschiedene Datenbanktypen, d.h. eine Datenabfrage für MySQL funktioniert für die meisten Nutzer, aber nicht für alle. Zum anderen kann sich die Datenbankstruktur irgendwann einmal ändern, dann klappen solche Abfragen nicht mehr bzw. müssen angepasst werden. Ein Beispiel dazu ist gerade im webtrees-Forum diskutiert worden. Nicht elegant, weil man das nicht von webtrees aus startet, sondern von der Datenbankverwaltung aus, aber eventuell doch für Dich machbar.
Hatte ich. Der Beitrag ist nicht mehr auffindbar, wurde damals aber nicht gerade euphorisch aufgenommen, mal vorsichtig ausgedrückt.
Der Gedanke, in der mysql-Datenbank direkt Abfragen auszuführen, ist für mich neu, aber durchaus vorstellbar. Zumindest könnte man sich mal einlesen und in entsprechenden Foren (bei mysql-Profis) um Hilfe nachfragen.
Jemand, der ehrgeiziger ist als ich, könnte damit ein Modul erstellen und die Ausgabe schöner machen:
Im von Dir verlinkten Beitrag ging der Vorschlag (siehe oben) allerdings in die Richtung, dass es direkt aus Webtrees heraus läuft. Das würde ich natürlich auch eleganter finden.
Nochmal einen Schritt zurück und etwas grundsätzlicher über Abfragen aller Art nachgedacht: Welchen Zweck sollen sie erfüllen? Ich sehe da zwei Felder, einmal die tägliche Arbeit erleichtern und dann Auswertungen (Berichte) aller Art erstellen.
Zu den täglichen Aufgaben gehören für mich Abfragen wie: zeige mir alle Datensätze ohne Quellenangaben, … alle „unvollständigen“ Datensätze (es fehlt bspw. das Sterbedatum), … alle verwandten Personen, die keine Taufpaten haben, … alle Datensätze bei der die Quelle xy ergänzt werden muss usw. Diese Abfragen kann ich dank Forschungsaufgabe in Verbindung mit der Erweiterten Suche in der V 1.7 ausführen.
Das zweite Feld sind die Auswertungen. Diese braucht man nicht täglich, aber wenn sie machbar sind, sind sie ein großes Potential. Beispiel: Zeige mir alle Brauhausbesitzer um 1795. Eine solche Abfrage braucht Niemand? Ich schon. , siehe Ideen Stipendienarbeit Punkt d). Das ist nur ein Beispiel und soll verdeutlichen, dass wir alle miteinander sehr viel mehr aus unseren Daten herausholen können, wenn wir sie entsprechend aufbereiten.
Vielleicht sind die Auswertungen ja tatsächlich relativ einfach mit phpMyAdmin umzusetzen, ich muss mich einlesen. Oder man füttert eben gleich ChatGPT mit der sql-Datenbank.
Das war ein Beitrag im Forum, aber kein „issue“, d.h. kein Auftrag an Greg etwas zu tun. Es gibt anscheinend nicht allzuviele Nutzer der ToDo-Funktion, die ja auch eher als rudimentär zu bezeichnen ist. Eigentlich müsste man da etwas mehr tun, etwa so wie die Funktion bei Gramps Web implementiert ist. Wenn Du noch einmal in zwei drei Sätzen Dein Problem mit der Research Task / ToDo formulieren könntest, dann mache ich ein issue daraus.
Nun, wenn man ein elegantes Erweiterungsmodul erstellt, das direkt mit Datenbankabfragen operiert, dann hat man genau die beiden von mir genannten Probleme: läuft das mit allen Datenbanktypen und läuft es nach einer Änderung der Datenbankstruktur immer noch? Und natürlich die Kernproblematik: um eine funktionierende SQL-Abfrage zu formulieren, müsste der Nutzer sich sehr gut mit SQL und mit der Tabellenstruktur von webtrees auskennen. Beides ist eher schwierig. So ein flexibles Modul wäre machbar, aber nicht mal so eben nebenbei. Im verlinkten Beitrag wurde gezeigt wie es quick-and-dirty direkt in der Datenbankverwaltung (etwa mit phpMyAdmin) geht.
Ja, dazu gab es einmal von ungeahnt, von Bogie, von Sir Peter, von mir und weiteren einen Beitrag im Forum. Dort wurden auch SQL-Abfragen der Datenbank diskutiert.
Das Problem ist, dass es nur eine Reihe von Berichten/Abfragen/Auswertungen gibt, die jeder gebrauchen kann. Es gibt aber individuell weiteren Bedarf, wie Dein Beispiel zeigt: „Zeige mir alle Brauhausbesitzer um 1795“. Wie befriedigt man diesen Bedarf am Besten?
Man braucht
eine spezifische Suche (so etwas wie: OCCU = Brauhausbesitzer AND BIRTH < 1795 < DEATH)
eine Aktion auf die Treffer (Anzeigen auf einer Karte, als Tabelle auflisten (Bildschirm/pdf), …)
Und man möchte solche Abfragen nicht jedes mal neu erfinden, wenn man sie alle paar Monate mal braucht.
Ich diskutiere gerade mit einem webtrees-Entwickler einen Weg in diese Richtung. Das würde dann für Dein Beispiel so aussehen:
Nutzen der vorhandenen Suche und der Filterfunktion so dass man ungefähr die Personen als Treffer hat, die man sich vorstellt.
Die Trefferliste in den Sammelbehälter legen. Dann kann man noch einzelne Personen dazu legen, die die Suche nicht gefunden hat, oder Personen ausschließen, die fehlerhaft gefunden worden sind. Solange bis man zufrieden ist.
Auf die Datensätze im Sammelbehälter legt man ein „Tag“, kennzeichnet diese Datensätze also in Deinem Beispiel mit „Brauhausbesitzer 1795“. Technisch ist das eine shared NOTE, die dem INDI hinzugefügt wird (sehr ähnlich wie Du spezielle _TODO den Datensätzen hinzufügst).
Dann kommt die Aktion: im Moment steht hier zur Verfügung: Visualisierung (mit GVExport, TAM oder LIN) oder Export als GEDCOM. Dazu soll kommen: Ausgabe als Tabelle.
Wenn man später diese Auswertung wieder braucht, legt man alle Datensätze mit dem Tag „Brauhausbesitzer 1795“ wieder in den Sammelbehälter, fügt ggf. neu hinzugekommene per Suche dazu, bzw. löscht welche und führt die Aktion zur Visualisierung oder Tabellenanzeige wieder aus.
Macht Das Sinn? Es ist der Versuch einen Mechanismus (und ein Vorgehen) anzubieten, der sehr individuelle Bedürfnisse befriedigen kann. Ohne dass man programmieren können muss.
Es freut mich sehr, dass es Überlegungen in Richtung Auswertungen gibt.
Mir würde es vollkommen genügen, wenn es die Möglichkeit bis hier hin (Trefferliste in den Sammelbehälter, Ausgabe als Gedcom) geben würde. Wenn ich dieselbe Abfrage Monate später wieder brauche, führe ich sie erneut aus. Sind die Datensätze mit einem „Tag“ versehen, ist das eigentlich ganz praktisch, aber ich müsste dann die vorhandenen („getagten“) Datensätze mit der neuen Trefferliste abgleichen. Das macht bei vielleicht 500 Treffern eine Menge Arbeit. Da geht es schneller die Abfrage neu auszuführen.
Ja, richtig. Die implementiere Erweiterte Suche ist da schon nah dran. Nach meinem Verständnis müsste man nach jedem(!) Ereignis, also bspw. auch Beruf, suchen können und die Zeitspanne müsste sich auch auf jedes Suchfeld eingrenzen lassen. Derzeit ist das nur für Geburt, Heirat und Tod mit der vorgegeben Auswahl „genau, +/- x Jahre“ möglich.
Ich behaupte mal, wenn man über alle Felder mit jedem eingrenzbaren Zeitraum suchen kann, kann man so ziemlich jede Abfrage ausführen. Die Königsdisziplin wäre, diese Suchfelder mehrmals zur Verfügung zu stellen. Es sollen also alle Brauereibesitzer 1795 gefunden werden, die auch (also UND) Schneider waren und vor 1799 verstorben sind.
Interessante Ideen. Zeigt aber auch, dass andere Webtreesnutzer ähnlich ticken. Fehlende Quellen und die Suche danach sind auch bei anderen ein wiederkehrendes Thema.
Später mehr zum Thema, auch das „issue“. Muss erstmal meinen Brot-und-Butter-Job erledigen.