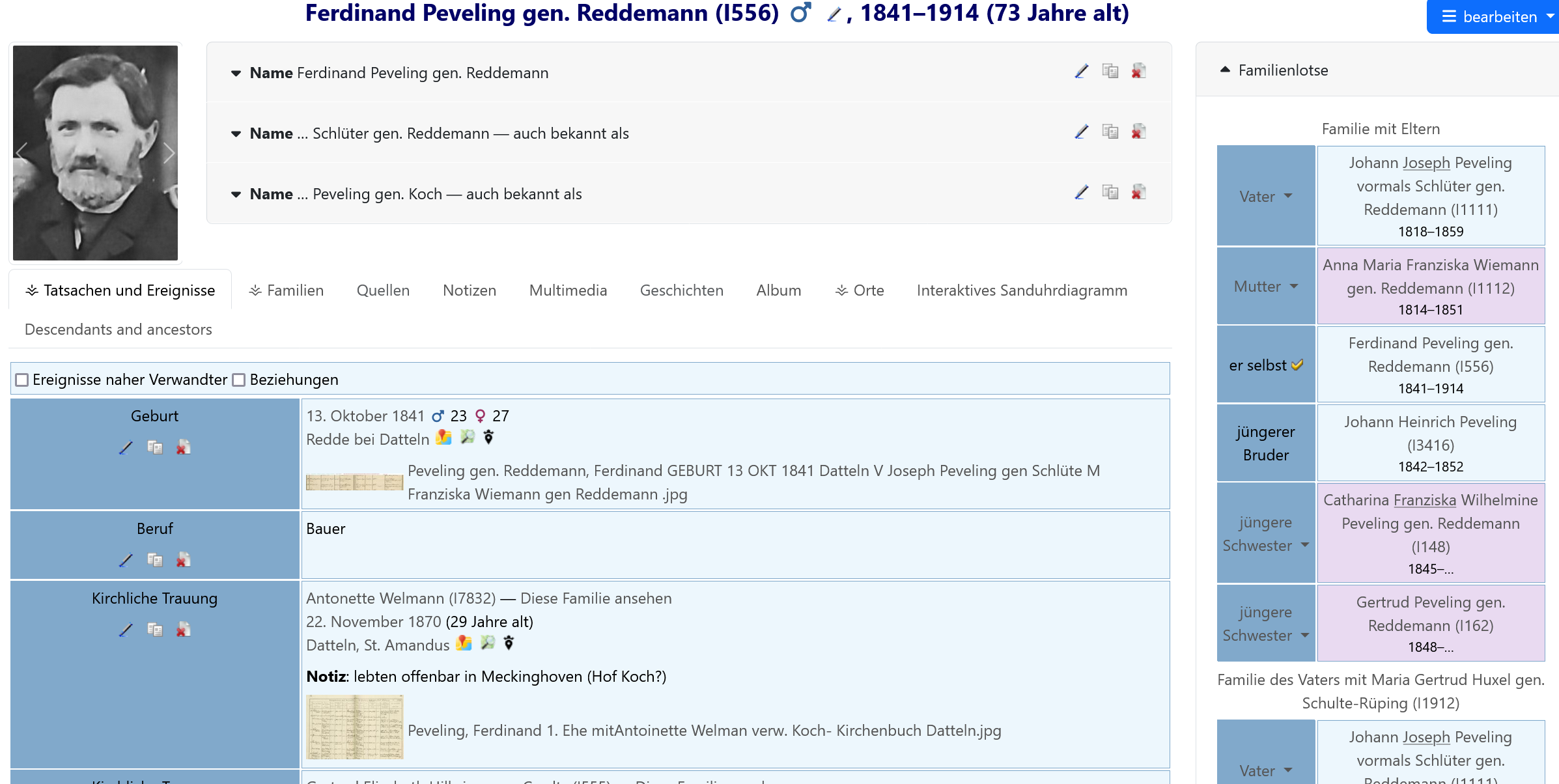
Ich möchte meine webtrees basierte Familiendatenbank gerne auch auf GEDBAS darstellen.
Den weitaus größten Teil meiner Daten habe ich selbst über online-Kirchenbücher (Matricula, Archion) zusammengetragen. Leider habe ich meine Quellen dabei überwiegend nur durch als Medien hochgeladene Screenshots der Kirchenbucheinträge, ergänzt durch einen ins Foto eingefügten Link aus Matricula/Archion dokumentiert (Beispiel siehe Anlagen) und keine Quellen-Felder ausgefüllt. Erst seit relativ kurzer Zeit mache ich zusätzlich Angaben in Quellen-Feldern.
Ich fürchte, eine händische Nacharbeit wäre bei über 5000 Personen, ca 1600 Familien und ca. 3000 Medien zu aufwändig.
Wäre eine KI-basierte Lösung zum Auslesen der Links und nachträglichen Einfügen als Quellen-Info denkbar bzw. machbar?
Hat es einen Wert, die Daten auch ohne Ergänzung in GEDBAS einzustellen?
Sind die Dateien halbwegs eindeutig benannt? Vielleicht lässt sich da ja etwas basteln, dass die Dateinamen der Anhänge ins Quellenfeld einer GEDCOM schreibt, so dieses leer ist
Zu deiner ersten Frage: ja, da geht mit KI sicher etwas. Du kannst etwa ChatGPT ein solches Quellenfoto zeigen (das setzt eventuell die Bezahlversion voraus) und beschreiben welche Informationen man im Bild am oberen Rand sieht. Und dass Du diese Informationen gerne als Tabelle hättest. Wenn das zuverlässig klappt, kannst Du ChatGPT sagen wie aus diesen Informationen ein GEDCOM-Quellendatensatz bzw. ein Quellenzitat aufgebaut werden soll. Das Ergebnis kannst Du dann mit Copy&Paste per RAW-GEDCOM-Bearbeitung in webtrees einfügen.
Zu Deiner zweiten Frage: Ja, das macht immer Sinn. Es gibt ein Erweiterungsmodul für webtrees, das speziell für den Export nach GEDBAS entwickelte Filter enthält. Diese nehmen zB lebende Personen vom Export aus, filtern Quellen und Notizen. Das wird bei der Kooperation zwischen CompGen und GenOnline genutzt.
Wenn sich aus dem Dateinamen oder aus dem Titel im Medienobjekt in webtrees die Herkunft ableiten lässt, dann kann als Quellenangabe zum Bespiel „Kirchenbuchauszug aus Matricula“ hinzugefügt werden. Wenn nicht, kannst Du immer noch als Quelle „Kirchenbuchauszug im Eigenbestand“ verwenden. Das Bild hast Du derzeit direkt dem Ereignis zugeordnet. Ich würde bei einer Umstellung das Bild dem Quellenzitat zuordnen. Ein geeignetes Tool kann bei der Anpassung der GEDCOM hier unterstützen.
Alternativ kannst Du beim Erstellen der GEDCOM für GEDBAS als Quellenangabe im Personensatz einen Link auf die Person in Deiner webtrees-Anwendung angeben. Wird dann der Link aus GEDBAS ausgeführt, dann sieht der Anwender die Personenansicht der Person wie in Deinem Beispiel dargestellt. Sollte der zugehörige Stammbaum für Besucher nicht freigegeben sein, dann erhält der Anwender die Anmeldeseite und kann sich hierüber direkt an den Admin der Anwendung wenden.
Für die letzt genannte Möglichkeit gibt es für webtrees das Zusatzmodul Extended_Import_Export. Im Auslieferungsumfang des Moduls gibt es auch bereits einen fertigen Filter für einen GEDBAS-Extrakt der BMD-Daten (Geburt/Heirat/Tod) mit den zusätzlichen Links zu den Personen in webtrees.
Ich würde die Daten so wie sie sind in Gedbas einstellen. Es gibt jede Menge Leute dort, die die Quellen nicht
freigegeben haben, was ich verstehen kann. Wer dann irgendwas findet, das ihn interessiert, der kann sich dann
an den Einsteller wenden. Das wäre für mich die einfachste und sinnvollste Lösung.
KI-Hilfe kannst du ja probieren, Hermann Hartenthaler hat eine Möglichkeit genannt, aber letztlich muss man der
KI dann vertrauen, dass sie alles richtig macht, nicht halluziniert. Ich würde mich nicht darauf verlassen. Und wenn man
dann alle Daten überprüfen müsste, dann könnte man es auch gleich alles selber machen.
Bei so einer Aufgabe halluziniert eine KI nicht, aber sie kann natürlich bei der Erkennung der Zeichen im Bild Fehler machen. Ja, deshalb muss man kontrollieren. Das geht aber viel schneller als selber tippen. Halluzinieren wurde die KI, wenn man ihr sagen würde: denke dir eine zu diesem Bild passende Quellenangabe aus. Aber nicht wenn man ihr sagt: lies was da steht und packe den Text so und so in einen GEDCOM-Quellendatensatz.
Ich habe das Halluzinieren schon in so vielen Fällen erlebt, dass ich nie sagen würde sie tut es in diesen oder jenen Fällen nicht.
Letztlich halluziniert sie immer dann, wenn sie eine Antwort geben soll, die sie nicht weiß, also erfindet sie etwas, was leider glaubhaft klingt, aber nicht immer leicht zu überprüfen ist.
Wenn sie Text erkennen soll, es aber nicht richtig kann, dann kann man sagen sie hat da Fehler gemacht. Man könnte auch sagen, sie
hat da etwas erfunden, also halluziniert. Müsste man genauer prüfen, was genau dahintersteckt.
Für den Anwender ist es doch egal, was die Ursache ist: das Ergebnis muss überprüft werden, mit dem Original verglichen werden.
Ich finde nicht, dass es so schneller geht, aber das muss jeder selbst für sich entscheiden, ist wohl auch Geschmackssache.
Hermann_Hartenthaler
Januar
Bernd.Schmidt:
letztlich muss man der
KI dann vertrauen, dass sie alles richtig macht, nicht halluziniert.
Bei so einer Aufgabe halluziniert eine KI nicht, aber sie kann natürlich bei der Erkennung der Zeichen im Bild Fehler machen. Ja, deshalb muss man kontrollieren. Das geht aber viel schneller als selber tippen. Halluzinieren wurde die KI, wenn man ihr sagen würde: denke dir eine zu diesem Bild passende Quellenangabe aus. Aber nicht wenn man ihr sagt: lies was da steht und packe den Text so und so in einen GEDCOM-Quellendatensatz.
Ganz herzlichen Dank für die vielen konstruktiven Hinweise.
Ich werde jetzt meine Daten erst mal wie sie sind in GEDBAS hochladen.
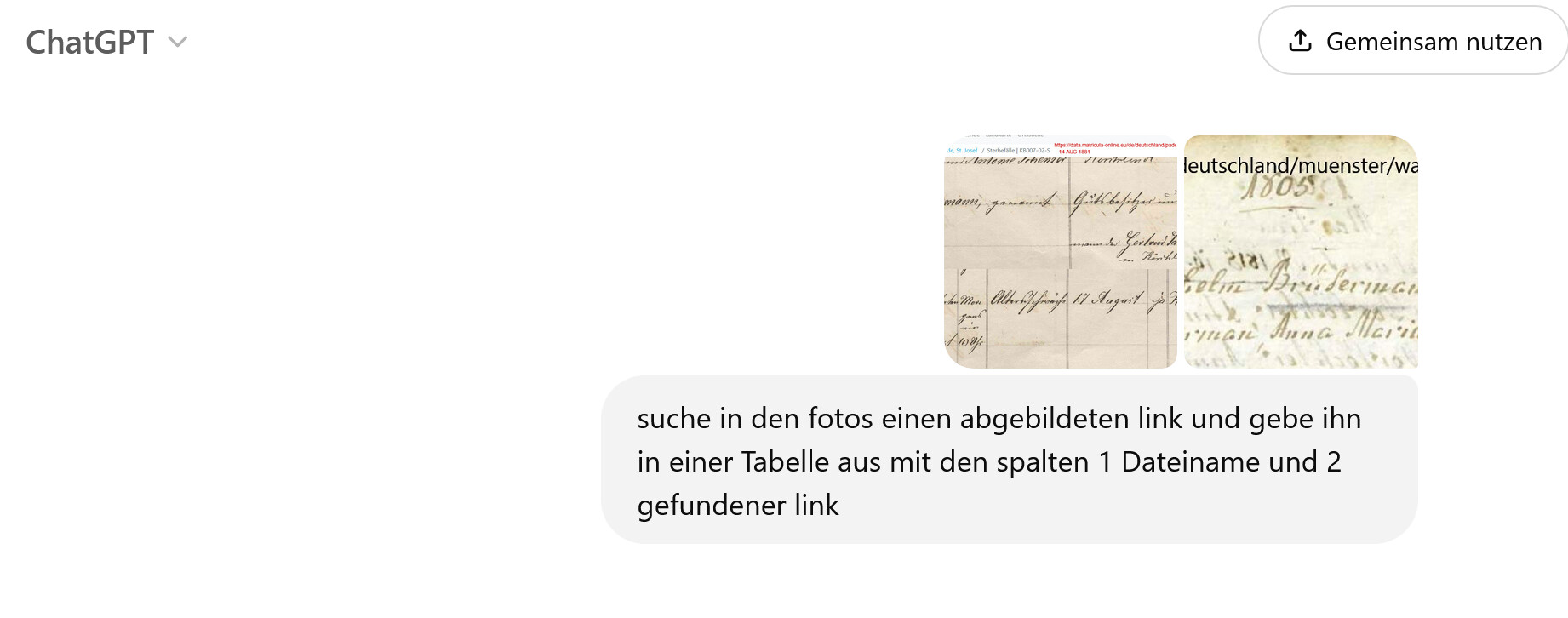
Unabhängig davon will ich versuchen, die abgebildeten Links aus den Medienobjekten mit ChatGPT auszulesen.
Erste Versuche mit zwei hochgeladenen Dateien waren erfolgreich:
Ich möchte hier Rückmeldungen geben über meine Erfahrungen bei dem Versuch, wie von @Hermann_Hartenthaler vorgeschlagen zu verfahren.
Gleich vorweg: eine komplette Erkennung meiner ca. 1000 zu durchsuchenden Dateien mit ChatGPT scheidet wohl leider aus, weil nur jeweils 10 Dateien hochgeladen werden können.
ChatGPT hat daher nach meinen Anweisungen ein Python Script gebaut, das mehrere Schritte erledigt:
Ausgangspunkt war eine Excel Datei die ich mit GedTool aus einem Test-Ausschnitt meiner webtrees-DB erstellt hatte, nämlich die Tabelle OBJE, in der u.a. alle verwendeten Medien mit dem Medien-ID (@M1234@) und dem Filenamen stehen.
in der Tabelle werden alle Mediendateien gefiltert, die möglicherweise die Abbildung eines Links enthalten können (erkennbar am von mir bei Screenshots von Kirchenbüchern vergebenen Namensbestandteil „GEBURT“|„HEIRAT“|„TOD“).
alle herausgefilterten Dateien werden mit dem OCR-Programm Tesseract auf enthaltene Textstrings durchsucht, die mit „http“ beginnen
die gefundenen Textstrings werden in der Exceldatei in einer weiteren Spalte zu dem jeweiligen Dateinamen ergänzt.
zusätzlich wird eine Spalte gefüllt, je nachdem welcher Text in dem Link gefunden wurde („Matricula“|„Archion“|„Archive NRW“|„FamilySearch“)
Im Prinzip habe ich damit eine Tabelle, mit der man mit GedTool und etwas Excel-Vodoo (@Hermann_Hartenthaler) die generelle Quelle (Matricula etc.) und den gefundenen Link in entsprechende SOUR-Felder eintragen könnte.
Wenn nicht die lokale Texterkennung so schlecht wäre!
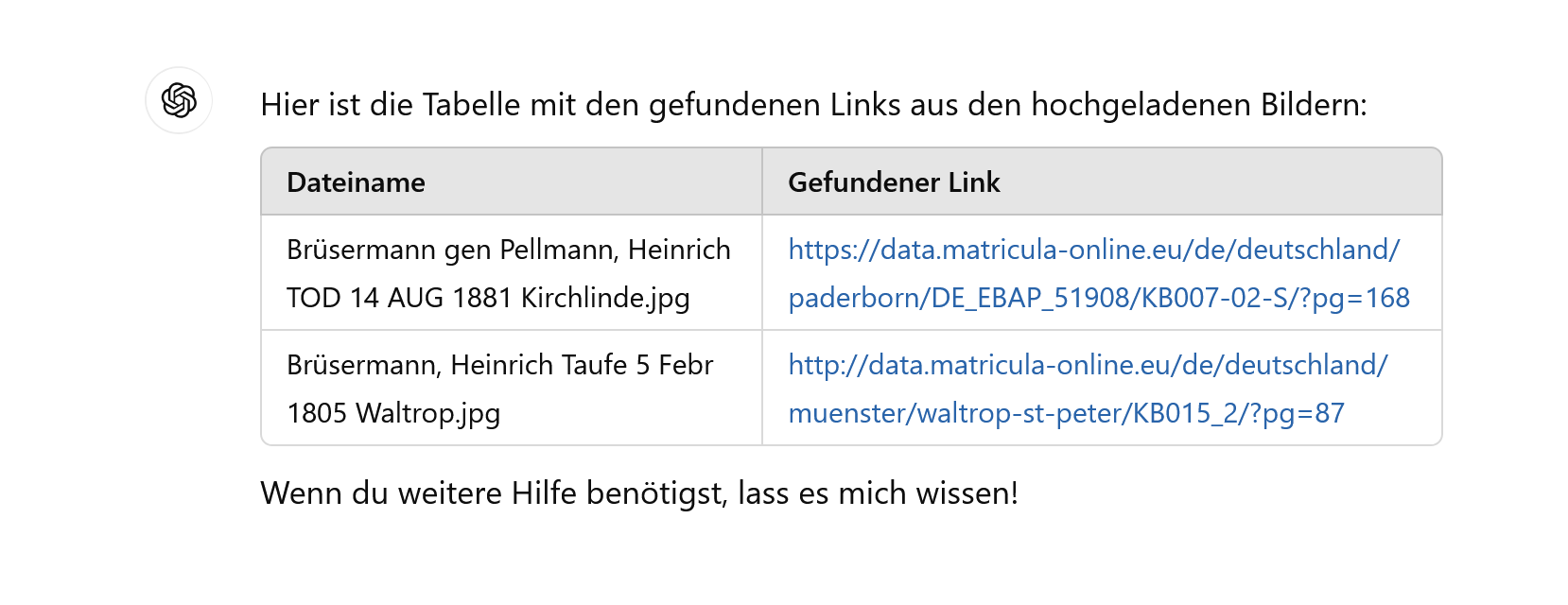
Nachfolgende Tabelle vergleicht für 6 Dateien das Fundergebnis direkt in ChatGPT und lokal mit Tesseract:
Dateiname
ChatGPT Gefundener Link
Tesseract gefundene Links
richtig?
richtig?
Brüsermann gen Pellmann, Heinrich Heirat Anna Gertrud Sallermann 4 MAI 1844.jpg
kein Fund
ja
kein Fund
ja
Brüsermann gen Pellmann, Heinrich TOD 14 AUG 1881 Kirchlinde.jpg
Helf, Anton 32J V Ant Jos H Landw in Wattensch M Ann Gert Möllenbeck HEIRAT 27 MAI 1853 Bochum Antonia Sulmann 22J V Ernst S M Syb Heimann Holthausen.jpg
ChatGPT gibt 2 von 4 nachprüfbaren Links korrekt wieder, in einem weiteren Link sind zwei Zeichen unterschlagen und der vierte Link würde prinzipiell funktionieren , wenn nicht bei Matricula die Pfarrei unbenant worden wäre.
Dagegen können bei Tesseract 4 von 5 gefundenen Links schon formal nicht funktionieren. Nur ein einziger wäre prinzipiell brauchbar (siehe oben).
Trotz des unbefriedigenden Ergebnisses bei der lokale Texterkennung bin ich sehr beeindruckt von der Arbeitsweise und Mächtigkeit von ChatGPT:
Ich habe bis vor 30 Jahren auf Großrechnern mit Fortran und APL gearbeitet und nutze sonst nur die grafische Windows Oberfläche. Ich wurde präzise angewiesen, python und Tesseract auf Kommandozeilen-Ebene zu installieren. Wenn das von ChatGPT vorgeschlagene Script falsch arbeitete oder Fehler auftraten, habe ich nach genauer Fehlerbeschreibung oder bloßem Hochladen der Fehlermeldung präzise Hilfe bekommen.
Zusammengefasst: Es war ein beeindruckendes Erlebnis, ChatGPT anzuwenden aber die Quellen-Einträge in meiner webtrees-DB werden wohl nicht nachgetragen werden.
Evtl. bleibt nur, wie von @Peter_S geraten, die Bilder dem Quellenzitat zuzuordnen.
Wenn die Dateinamen ein festes Schema haben, könnte man sie ja auch per Excel oder Python noch etwas anhübschen, bevor man sie in das Quellenfeld schreibt. Wie gesagt, ich würde vermutlich ein Python-Skript vorschlagen, um diese Bearbeitung am Ende direkt in der GEDCOM vornehmen zu können.