Originally published at: Neue Wege, gedruckte serielle Quellen zu erschließen • Verein für Computergenealogie e.V. (CompGen)
Schon mit den Verlustlisten Österreich-Ungarns haben wir eine neue Herangehensweise gewählt, um umfangreiche, gedruckte, serielle Quellen für die Familien- und Ahnenforschung zu erschließen. Anders als bei den deutschen Verlustlisten des Ersten Weltkriegs haben wir dabei nicht nur auf menschliche Arbeit gesetzt. Viele Schritte kann ein Computerprogramm gut und viel schneller erledigen. In diesem englischen Artikel habe ich vor einiger Zeit das Vorgehen bei den Verlustlisten Österreich-Ungarn bereits beschrieben.
Grundlegender Ablauf
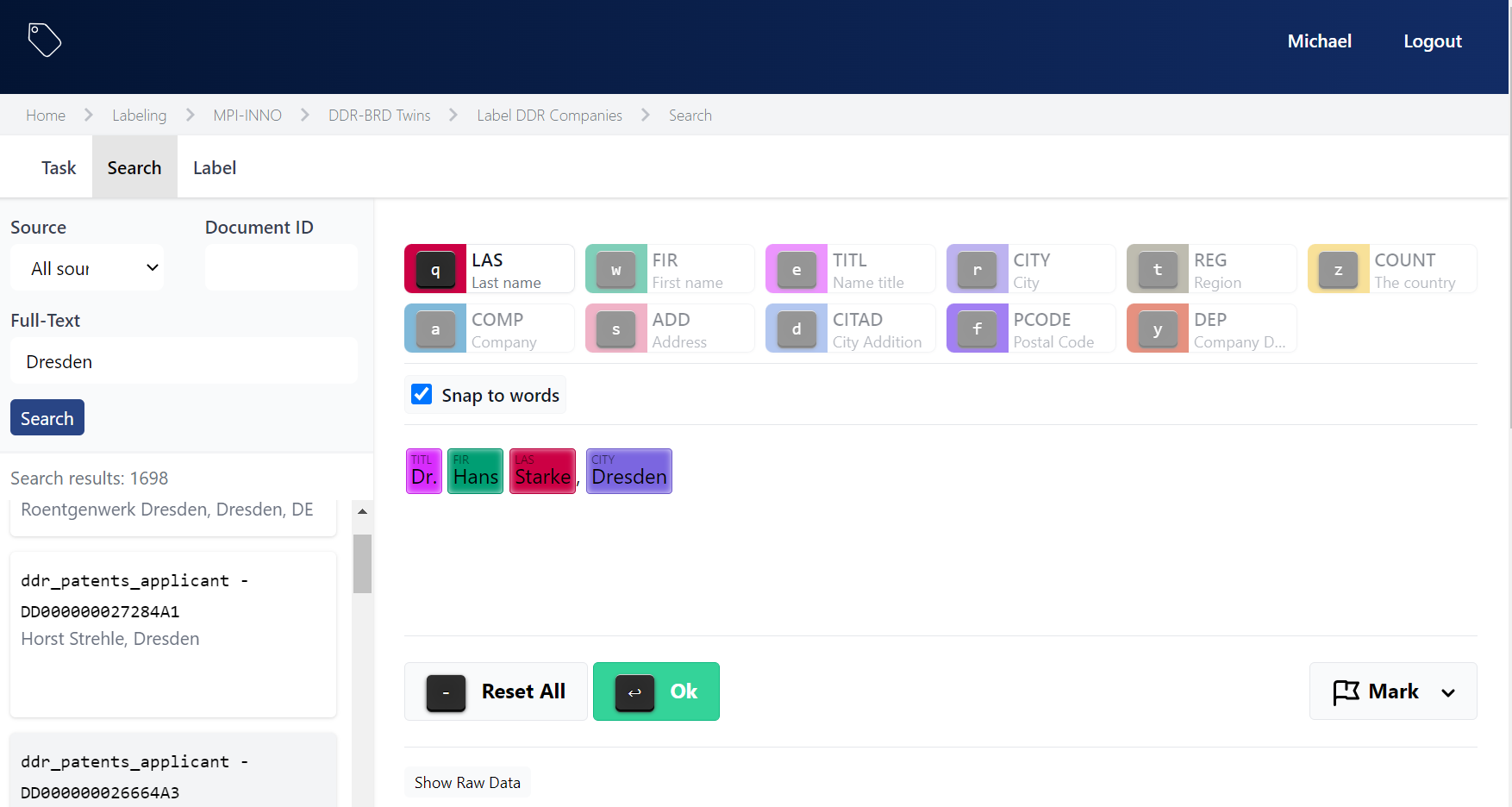
Ganz grundlegend teilt sich das Vorgehen von der gescannten Quelle bis hin zu den fertigen, strukturierten Daten in folgende Schritte auf:
- maschinelle Texterkennung (OCR)
- Aufbereiten der OCR-Texte
- manuelle Nacharbeit
Bei den Verlustlisten Österreich-Ungarns haben wir die maschinelle Texterkennung mit Hilfe von ABBYY FineReader XIX durchgeführt. Die Qualität war schon in Ordnung; mittlerweile hat sich in dem Bereich aber noch einiges getan, so dass die Erkennungsrate der Wörter nahe an 100 % ist. Die Aufbereitung der Texte erfolgte mit einem eigens entwickelten Programm, das spezielle Regel für die Struktur der österreich-ungarischen Verlustlisten einprogrammiert hat. Die manuelle Nacharbeit erfolgte schließlich im Dateneingabesystem (DES), wo fehlende Teile eines Eintrags ergänzt und falsch erkannte Wörter korrigiert wurden.
Aufbereiten der OCR-Texte
Auf das Aufbereiten der OCR-Texte möchte ich im Folgenden genauer eingehen. Dort habe ich nämlich mit Hilfe von maschinellem Lernen (machine learning) gute Fortschritte erzielt. Die Ergebnisse sind so gut, dass man auch über neue Wege der manuellen Nacharbeit nachdenken sollte.
Zwei Arbeitsschritte sind zu erledigen:
- Defragmentieren der Einträge
- Erkennung der Struktur eines Eintrags
Defragmentieren
Würde in der Quelle eine Zeile genau einem Eintrag entsprechen, so könnte der Arbeitsschritt Defragmentieren entfallen. Meist gehören jedoch mehrere Zeilen zu einem Eintrag. Noch komplizierter ist es, wenn innerhalb einer Zeile mehrere Einträge enthalten sind, die sich darüber hinaus auch noch über mehrere Zeilen erstrecken können. Mit diesem Problem habe ich mich aber noch nicht beschäftigt. Ziel des Arbeitsschrittes Defragmentieren ist es also, den Text eines Eintrags in eine Zeile zu bekommen. Bei den bisher bearbeiteten Quellen konnte man Einträge gut über die Einrückung erkennen.

Erkennen der Struktur
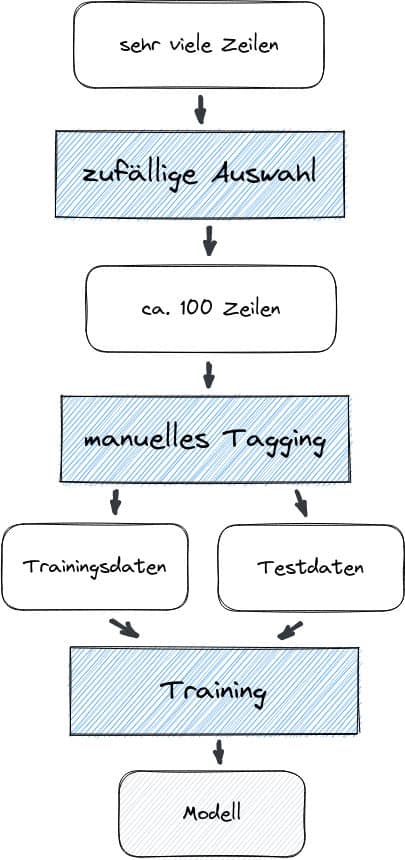
Als nächstes muss der Text eines Eintrags in seine Bestandteile zerlegt werden. Leider kann man nicht einfach Komma oder ähnliches als Trennzeichen verwenden – nicht alle Bestandteile sind durch Komma getrennt und manchmal macht die OCR einen Punkt daraus. Außerdem sind nicht immer alle Bestandteile für einen Eintrag enthalten und gelegentlich weicht auch die Reihenfolge der Bestandteile ab. Daher kommt an dieser Stelle maschinelles Lernen (chunking) zum Einsatz. Aus der gesamten Menge der Zeilen wird ein Teil (z.B. 100 Zeilen) genommen und von Hand markiert.

Praktisch kann man sogar mit weniger Zeilen starten, dann die Erkennung laufen lassen und das (zunächst schlechte) Ergebnis weiter verbessern. Die 100 Zeilen teilt man in Trainingsdaten und Testdaten auf; als praktikabel hat sich ein Verhältnis von 80:20 bis 90:10 erwiesen.
Mit den Trainingsdaten trainiert man ein Modell. Die Testdaten verwendet man, um zu überprüfen, wie gut die Erkennung mit dem trainierten Modell funktioniert. Ist man mit den Ergebnissen des Trainings zufrieden, kann man die gesamte Menge der Zeilen zerlegen. Natürlich kann man immer noch später weitere richtige bzw. korrigierte Einträge den Trainings- und Testdaten hinzufügen.
Konkret habe ich ein conditional random field für das chunking verwendet. Bei der Erkennung von features habe ich mich auf rudimentäre Informationen beschränkt. Da steckt bestimmt noch viel Potential drin. Dem Modell fehlt außerdem noch das “Wissen” über die innere Struktur eines Eintrags. Wenn z.B. der Dienstrang genannt wurde, dann kann ein späteres Wort nicht nochmal der Dienstrang sein.
Den Java-Code für die gesamte Aufbereitung kann man sich hier ansehen: https://gitlab.genealogy.net/jzedlitz/ocr4des Da die einzelnen Zwischenergebnisse immer wieder als Textdateien gespeichert werden, könnte man auch gut unterschiedliche Programmiersprachen für die einzelnen Schritte verwenden.
Das Vorbereiten der Trainingsdaten erfolgt bisher ganz simpel in Textdateien. Sinnvoll wäre es, die Arbeit auf mehrere Personen aufzuteilen. Fehler beim Markieren lassen sich nie ganz vermeiden. Falsche Markierungen haben aber negativen Einfluss auf das Training des Modells. Daher ist ein Abgleich mit mindestens zwei Eingaben unterschiedlicher Personen sinnvoll. Vielleicht hat jemand eine Idee, wie man das Markieren (auch Annotieren oder Taggen genannt) besser gestalten kann.
Manuelle Nacharbeit
Was macht man nun mit den automatisch strukturierten Einträgen? Ganz perfekt ist die Zerlegung nicht, bisherige Tests sind aber sehr gut. Man könnte die Daten in einer Tabelle nachbearbeiten. Durch geschicktes Sortieren und Suchen kann man bestimmt die problematischen Einträge schnell finden.
Bei den Verlustlisten Österreich-Ungarn haben wir die erkannten Einträge ins DES importiert und dort korrekturlesen bzw. ergänzen lassen. Das DES scheint mir bei der sehr guten Datenqualität nicht gut geeignet zu sein. Es ist nämlich sehr ermüdend, wenn man über 90 % der Einträge einfach nur noch “abnicken” muss, da die maschinelle Erkennung schon so gut war. Denkbar wäre eine neue Webanwendung, die einem unklare Einträge anzeigt und fragt, ob daran eine Korrektur notwendig ist. Das könnte man dann auch bequem auf einem Smartphone oder Tablet machen.
Eine andere Möglichkeit könnte es sein, das DES um einen neuen Modus zu erweitern, bei dem man gezielt zu Seiten mit unklaren Einträgen springen kann, am besten direkt zum Eintrag. Dort könnte man die Korrektur und auch gleich die Verbesserung vornehmen.
Auch hier würde ich mich über Idee freuen, wie wir die maschinell strukturierten Daten am besten nachbearbeiten können.