Originally published at: Kann man gedruckte Ortsfamilienbücher mit KI auswerten? • Verein für Computergenealogie e.V. (CompGen)
Dass Ortsfamilienbücher exzellente Forschungsgrundlagen für die Geschichts-, Wirtschafts- und Sozialwissenschaften liefern, haben Georg Fertig, Robert Stelter und Christian Boose bereits im Oktober 2022 hier im Blog des Vereins für Computergenealogie (CompGen) ausführlich beschrieben. Aber kann man auch gedruckte Ortsfamilienbücher (OFB) mit künstlicher Intelligenz (KI) oder anderen Methoden auswerten? Dieser Frage gehen Robert Stelter und Rafael Biehler in ihrer kürzlich veröffentlichten Arbeit nach.
Vergleich von drei Methoden an drei Ortsfamilienbüchern
In der Arbeit werden die Ergebnisse von KI-gesteuerter, Python-Code-basierter und manueller Datenabfrage anhand von Stichproben von 30 zufällig gewählten Familien aus drei Ortsfamilienbüchern verglichen. Die ausgewählten Ortsfamilienbücher unterscheiden sich in Erscheinungsjahr, geographischer Lage, Familienzahl und Religionszugehörigkeit, ordnen aber die Familien immer nach den Männern. Jede Familie hat eine eindeutige ID, bei Mehrfachehen werden neue IDs vergeben.
- Ortssippenbuch der Gemeinde Ottersdorf im Ried, Stadtteil von Rastatt 1700–1913 von E. Hahner und E. Burster (2000)
- Ortssippenbuch Schafhausen mit vielen Evangelischen aus Dätzingen und Weil der Stadt 1525–1997 von E.C. Haag (1997)
- Familienbuch Zschortau bei Leipzig von E.-N. Kunath (2009)
Die Strukturen in der Darstellung der Familien sind unterschiedlich, weswegen die Abfragen für jedes Buch angepasst werden müssen. Ob eine KI-Anwendung sich auf diese Varianten anpassen kann, ist die große Frage.
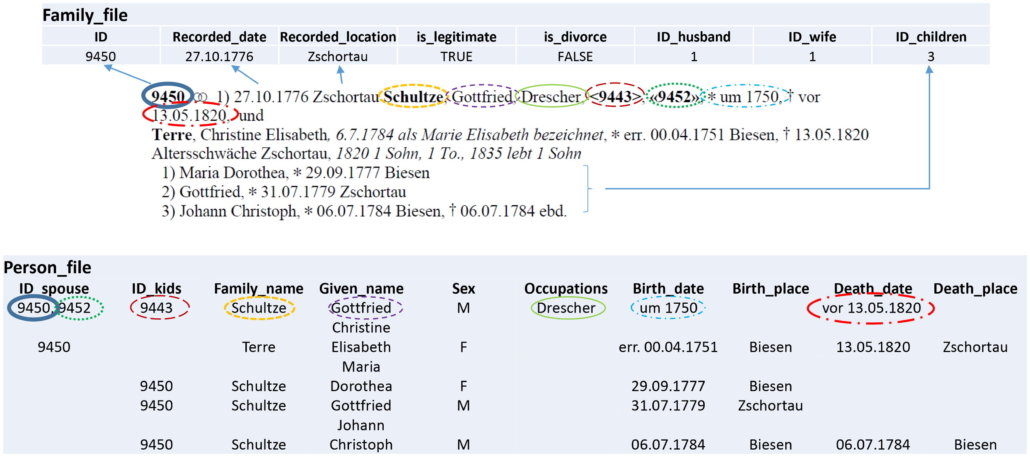
In der manuellen Methode wurden zunächst die Stichproben in Familien- und Personendateien extrahiert. Diese Tabellen definieren die Zielmarke. Die Abfrage mit einem Python-Code erfolgte in fünf Stufen. Das Problem der Geschlechtsbestimmung von Kindern und Einzelpersonen wurde mit Hilfe der OFBscientificDatabase gelöst.
Drei verschiedene KI-Modelle wurden getestet: GPT-3.5 Turbo, GPT-4.0 und Mixtral 8x7B, das heruntergeladen und lokal ausgeführt werden kann. Die KI wurde aufgefordert, Python-Objekte zu erstellen. Die Prompts sind in Anhang der Arbeit angeführt.
Ergebnisse
Die Bewertung der Verfahren im Vergleich zur manuellen Erfassung zeigt klar, dass der Python-basierte Code am besten funktionierte. Über 90 % der Werte wurden korrekt ermittelt. Die KI-Methoden mit GPT-3.5 schnitt am schlechtesten ab, GPT-4.0 besser. Die Zahl der Kinder wurde nicht immer korrekt ermittelt. Bei Datum und Ort der Heirat gab es Fehlmeldungen. Die drei Fälle lassen jedoch nicht den Schluss zu, dass der Python-Code auch für andere Ortsfamilienbücher ebenso gut funktioniert, die Qualität der Ergebnisse für die Verwendung der Daten ausreicht und die Ergebnisse auch auf andere historische Quellen übertragbar ist. Für die Anwendung der KI-Modelle sind Spezialisten und viel Erfahrung nötig.
Zur Prüfung des klassischen Python-Codes wurden weitere Test mit sechs weiteren Ortsfamilienbüchern (Brodau, Werbelin, Eisingen, Königsbach, Stein und Hardheim) durchgeführt. Grundsätzlich gab es keine Qualitätsunterschiede. Lediglich die Berufe wurden schlechter erfasst.