Hallo Bernhard,
das werde ich morgen mal machen.
Lade nur eine Testdatei hoch, da ist egal wie die heißt.
Dieses Test-Projekt wird dann wieder komplett gelöscht.
Hier mal eine Beschreibung warum ich das ausprobiere.
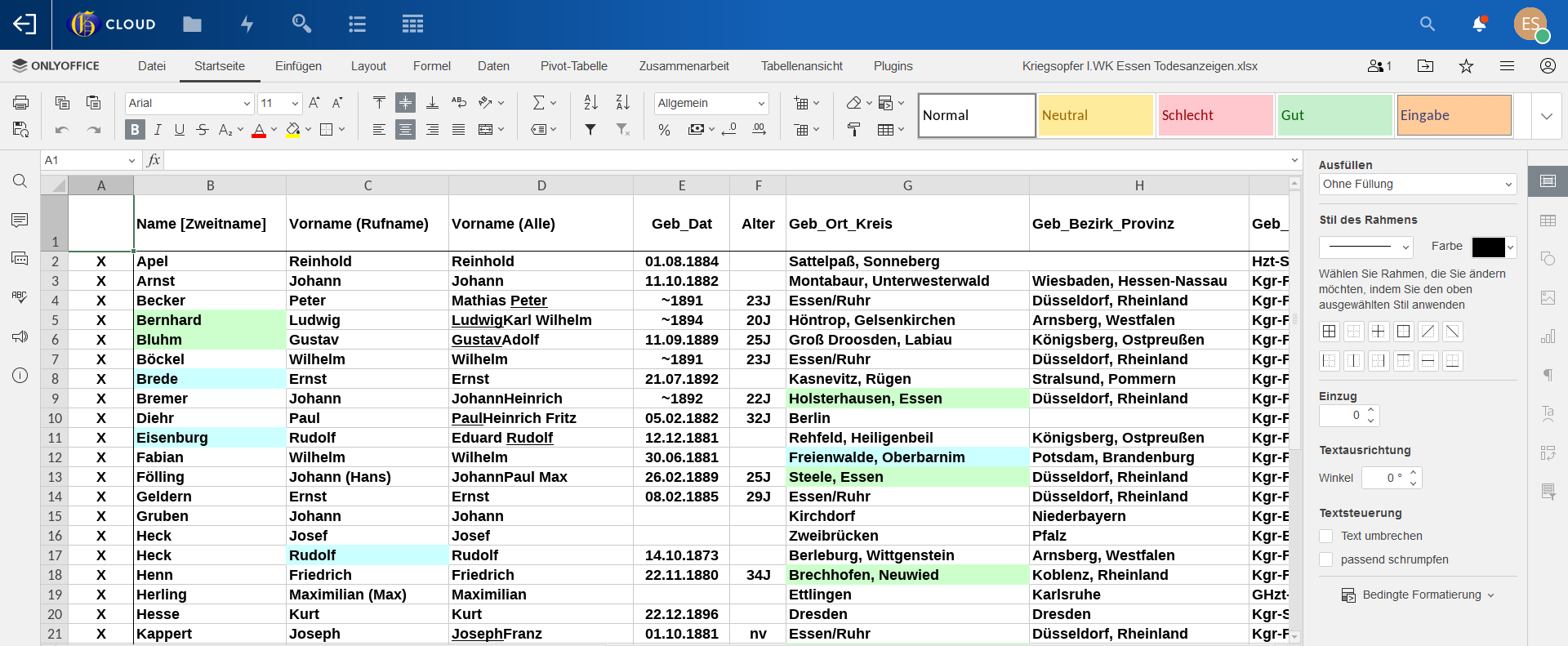
Ich habe eine Datei mit ca. 30.000 Essener Kriegsopfern.
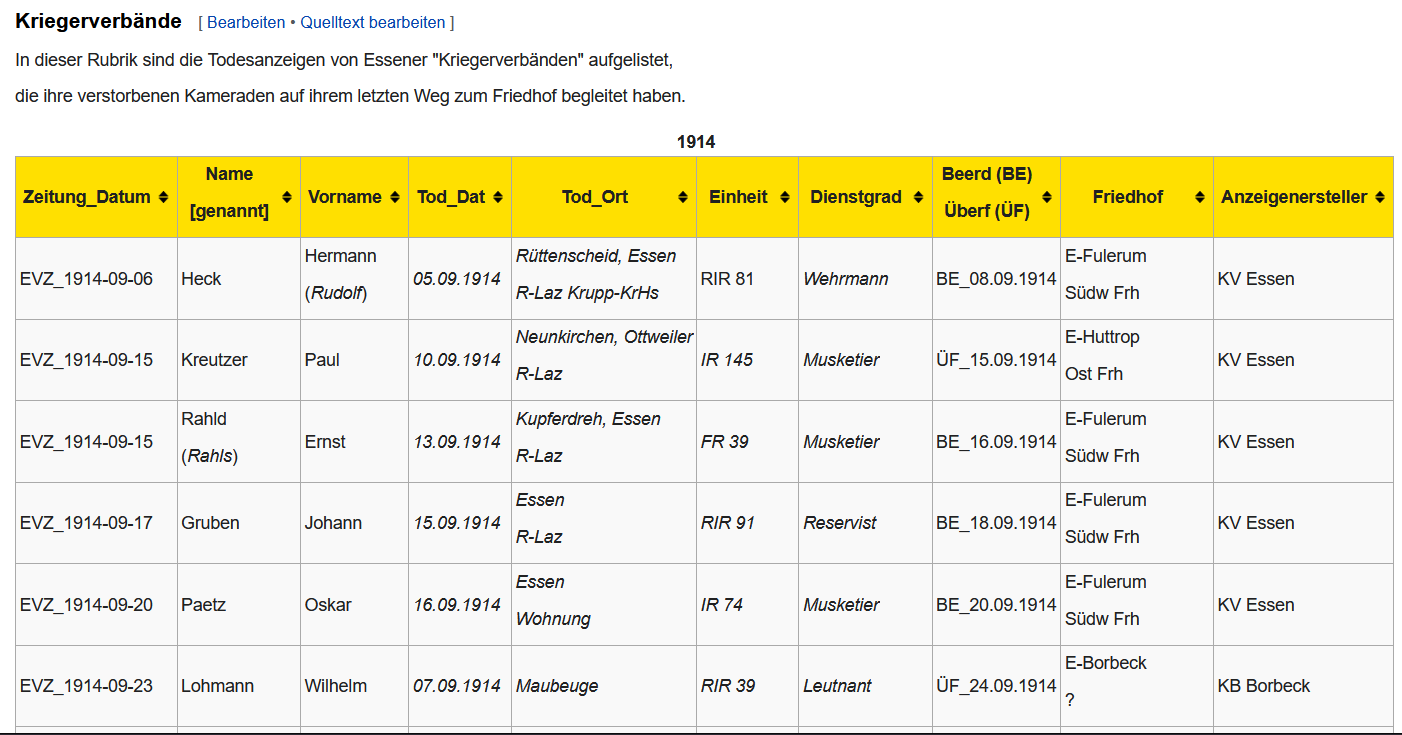
Aus dieser Datei veröffentliche ich gerade in GenWiki die
Todesanzeigen der Kriegervereine aus Essener Zeitungen.
https://wiki.genealogy.net/Kriegsopfer_I._WK_Essen_Todesanzeigen
Zu den Kriegsopfern der Todesanzeigen habe ich meistens
die kompl. Daten (aus vielen Quellen ergänzt) vorliegen.
Die kann ich aber nicht alle veröffentlichen, da die Tabelle
in GenWiki mit der Anzahl der Datenfelder nicht klarkommt.
Wenn es in der Team-Cloud eine „bessere“ Tabelle oder
Datenbank gäbe, könnte man ja dort alle vorh. Daten zu
den Todesanzeigen erfassen und nach GenWiki verlinken.
Wenn man ein wenig weiterdenkt, kann man auch gleich die
Daten aller Essener Kriegsopfer in einer Datenbank erfassen.
Diese Datenbank könnte dann von „Mitmachwilligen“, nach und
nach um weitere Kriegsopfer des I. Weltkrieges ergänzt werden.
Es gibt ja insgesamt ca. 2,2 Mio Kriegsopfer des I. Weltkrieges.
Aus dieser Gesamt-Kriegsopferdatenbank können dann
beliebige Auswertungen erstellt werden, z.B. alle Einträge
zu einem Datum, Zeitraum, Geb-/Wohn-/Todesort,
Verluststatus, Einheit, Dienstgrad, Todesanzeigen, .....
Auf die Veröffentlichung vieler Einzellisten mit Untermengen
aus dieser Gesamt-Datenbank könnte man dann verzichten.
Wie z.B. die Veröffentlichung der Todesanzeigen
Das könnte man dann alles, mit noch wesentlich mehr
Detailangaben, aus der Gesamt-Datenbank selektieren.
Bei einer Excel-Tabelle, einer GenWiki-Oberfläche oder
der Verlustliste I. WK ist man gewisse Standards bzgl.
Layoutgestaltung und Bedienfunktionalitäten gewohnt,
aber wie sieht das bei dieser Team-Cloud Lösung aus.
Und das möchte ich mir bei dem Test mal anschauen.
LG Eberhard