Sign in · GitLab im Produktiv Wiki hat sich das image - Verzeichnis anscheinend geändert. Ich bräuchte einen schellen Zugriff auf die Änderungen ab ca. August. Am Besten mit rsync. Brauche ich da spezielle Rechte für oder kann ich den Mount aus dem Produktivwiki einfach übernehmen?
Ich verstehe leider das Problem nicht. Wieso sollte etwas am Verzeichnis geändert worden sein?
Kannst du auf den Server vom Produktiv-Wiki zugreifen?
@robertpaessler Danke fürs kümmern.
Ja ich komme auf den Server vom Produktiv-Wiki. Dort findet sich
//u385564.your-storagebox.de/u385564-sub1/images 5.0T 2.7T 2.4T 53% /mnt/images-storagebox
172.16.6.1:/mnt/Volume_20TB/data_genwiki-images 3.3T 2.9T 374G 89% /mnt/images
172.16.6.1:/mnt/Volume_20TB/austausch 50G 25G 26G 50% /mnt/austausch
tmpfs 776M 0 776M 0% /run/user/1002
mit hart verdrahteten IP Adressen zu 172.16.6.1 - welcher Server ist das? Ich probier mal aus, was passiert, wenn ich den fstab Eintrag übernehme.
Im Ticket ist beschrieben wie ich jetzt erstmal eine SQL Datenbank erstellt habe die unseren
aktuellen Images Bestand wieder gibt. Zunächst habe ich das für den Stand vom August gemacht, der damals synchronisiert wurde.
content_query -li
file_count:file_count
tables:tables
size_histogram:size_histogram
filetype_histogram:filetype_histogram
search_by_date_extension:search_by_date_extension
largest_files:largest_files
directory_summary:directory_summary
user_count:user_count
table_count:table_count
find_pages:find_pages
ns_histogram:ns_histogram
ns_histogram_named:ns_histogram_named
```
content_query -qn file_count -f github
```
file_count
query
SELECT COUNT(*) as count FROM files;
result
| count |
|---|
| 8180393 |
```
content_query -qn size_histogram -f github
```
size_histogram
query
SELECT
CASE
WHEN size < 1024 THEN '0-1KB'
WHEN size < 10240 THEN '1-10KB'
WHEN size < 102400 THEN '10-100KB'
WHEN size < 1048576 THEN '100KB-1MB'
WHEN size < 10485760 THEN '1-10MB'
WHEN size < 104857600 THEN '10-100MB'
WHEN size < 1073741824 THEN '100MB-1GB'
ELSE '1GB+'
END as size_range,
COUNT(*) as count
FROM files
GROUP BY size_range
ORDER BY MIN(size);
result
| size_range | count |
|---|---|
| 0-1KB | 190370 |
| 1-10KB | 988604 |
| 10-100KB | 3436492 |
| 100KB-1MB | 2666331 |
| 1-10MB | 897994 |
| 10-100MB | 602 |
content_query -qn filetype_histogram -f github
content_query -qn filetype_histogram -f github
filetype_histogram
query
SELECT
CASE
WHEN ext = '' THEN 'no_extension'
ELSE ext
END as extension,
COUNT(*) as count
FROM files
GROUP BY ext
ORDER BY count DESC
LIMIT 50;
result
| extension | count |
|---|---|
| jpg | 5719177 |
| djvu | 1136386 |
| png | 1116533 |
| txt | 182261 |
| djbz | 14465 |
| jpeg | 3649 |
| gif | 1956 |
| 1745 | |
| html | 1079 |
| svg | 973 |
| tex | 712 |
| log | 712 |
| jpg_defekt | 477 |
| iff | 119 |
| png_defekt | 42 |
| thumb | 26 |
| ogg | 24 |
| no_extension | 11 |
| lock | 10 |
| gif_defekt | 6 |
| tmpfsfile | 4 |
| xls | 3 |
| mp3 | 3 |
| map | 3 |
| zip | 2 |
| webp | 2 |
| svn-base | 2 |
| ods | 2 |
| mm | 2 |
| ico | 2 |
| sh | 1 |
| ogv | 1 |
| kqegna | 1 |
| doc | 1 |
| basgpz | 1 |
Analyse und Aufräumplanung Wiki-Images
Von den 8 Millionen Dateien sind 6 Millionen von djvu erzeugt - die können allesamt aus dem Wiki-Bereich entfernt werden.
Eine Sicherungskopie sollte auf echten Datenträgern und nicht in der Cloud gemacht werden.
Die tar-Dateien werden dann für den produktiven Viewer verwendet, liegen aber nicht mehr im Wiki-Images Verzeichnis. Ich gehe davon aus, dass dort nichts Neues mehr hinzukommt.
Ansonsten sind jede Menge Aufräumarbeiten an den übrigen Dateien erforderlich - die würde ich allerdings größtenteils in das 1.43 Migrationsprojekt verschieben, da wir im Moment noch genug damit zu tun haben, überhaupt wieder produktiv zu werden.
Encoding-Problem bei Dateinamen
Problem
Wir haben 102 Dateien mit Encoding-Problemen identifiziert, z.B.:
Br\ufffdhl_Maria-von-den-Engeln_5126.jpg(sollteBrühlsein)Kr\ufffdnung_in_K\ufffdnigsberg_1701.JPG(sollteKrönung in Königsbergsein)
Ursache
\ufffd ist das Unicode-Ersatzzeichen (�), das erscheint wenn:
- Originaldateiname:
Brühlmit deutschem Umlaut ü - Datei wurde mit ISO-8859-1 oder Windows-1252 Encoding erstellt (Byte
0xFCfür ü) - Unser Script liest mit UTF-8 und
errors='replace' - Ungültiges UTF-8 Byte
0xFCwird durch\ufffdersetzt
Die 102 betroffenen Dateien enthalten vermutlich deutsche Umlaute:
- ä = 0xE4
- ö = 0xF6
- ü = 0xFC
- ß = 0xDF
Lösungsansätze
Option 1: Fix im Bash-Script
find . -type f -printf "%p|%s|%T+|%C+\n" | iconv -f ISO-8859-1 -t UTF-8 >> $target
Option 2: Akzeptieren und später fixen
Die encoding_issue-Spalte markiert diese 102 Dateien. Cleanup im Rahmen des 1.43 Migrationsprojekts durchführen.
Empfehlung
Für jetzt: Option 2 - Markierung behalten, im Migrationsprojekt bereinigen.
Die Sqlite-Datei kann man sich online über https://genwiki39.genealogy.net/sqlite/images
Anschauen username sqlite, passwort: HngnOm!FQ@m-.dh

Das ist unser Storage-Server in Bremen:
(Leider wurde unser Wiki im Gitlab beseitigt.)
Ich sehe da 10 495 Dateien mit Encoding-Problemen (select * from files where encoding_issue > 0); so weit ich sehen konnte alle mit Umlauten oder „ß“ im Dateinamen. Darunter auch recht neue Dateien etwa aus dem webtrees-Handbuch. Wie ist die Empfehlung: ä->ae, etc.? Das müsste ein Bot erledigen können - oder @BSchwend ?
Und warum liegen die Mediendateien des GenWiki noch in Bremen? War da nicht einmal die Rede vom Umzug in eine StorageBox?
Es wurden schon alle Daten zu Hetzner kopiert und getestet. Ich wünschte mir, dass dann die Storage Box von Hetzner an das neue GenWiki kann. Aber leider zeigten Tests, dass die Verbindung immer noch miserabel ist. Daher wollen wir zunächst aussortieren und weiter testen. Wolfgang bekommt direkten Zugang zu unserem Storage in Bremen.
1 „Gefällt mir“
Zum Aufräumen sollten wir IMHO einen „richtigen“ Server mit grosser SSD nehmen. Alles auf den Aufräumserver kopieren, dort die Scripte laufen lassen und dann erst zu Hetzner kopieren bzw. entscheiden welches Zugriffstempo wir brauchen. Für Wartung und Entwicklung ist mit Hetzner kein Staat zu machen. Das ist viel zu langsam und damit teuer.
Der RWTH Server und mein(e) Kellerserver sind geeignet. Das kann aber inzwischen jede AMD Ryzen Büchse für 1500 EUR und 2 x 300 EUR 4 TB SSD. Gibst beim CompGen auch noch richtige Rechner irgendwo?
In Bremen ![]()
Ich sehe 2 Optionen:
-
deinen Keller-Rechner nutzen
-
einen dedicated Server bei Hetzner nehmen:
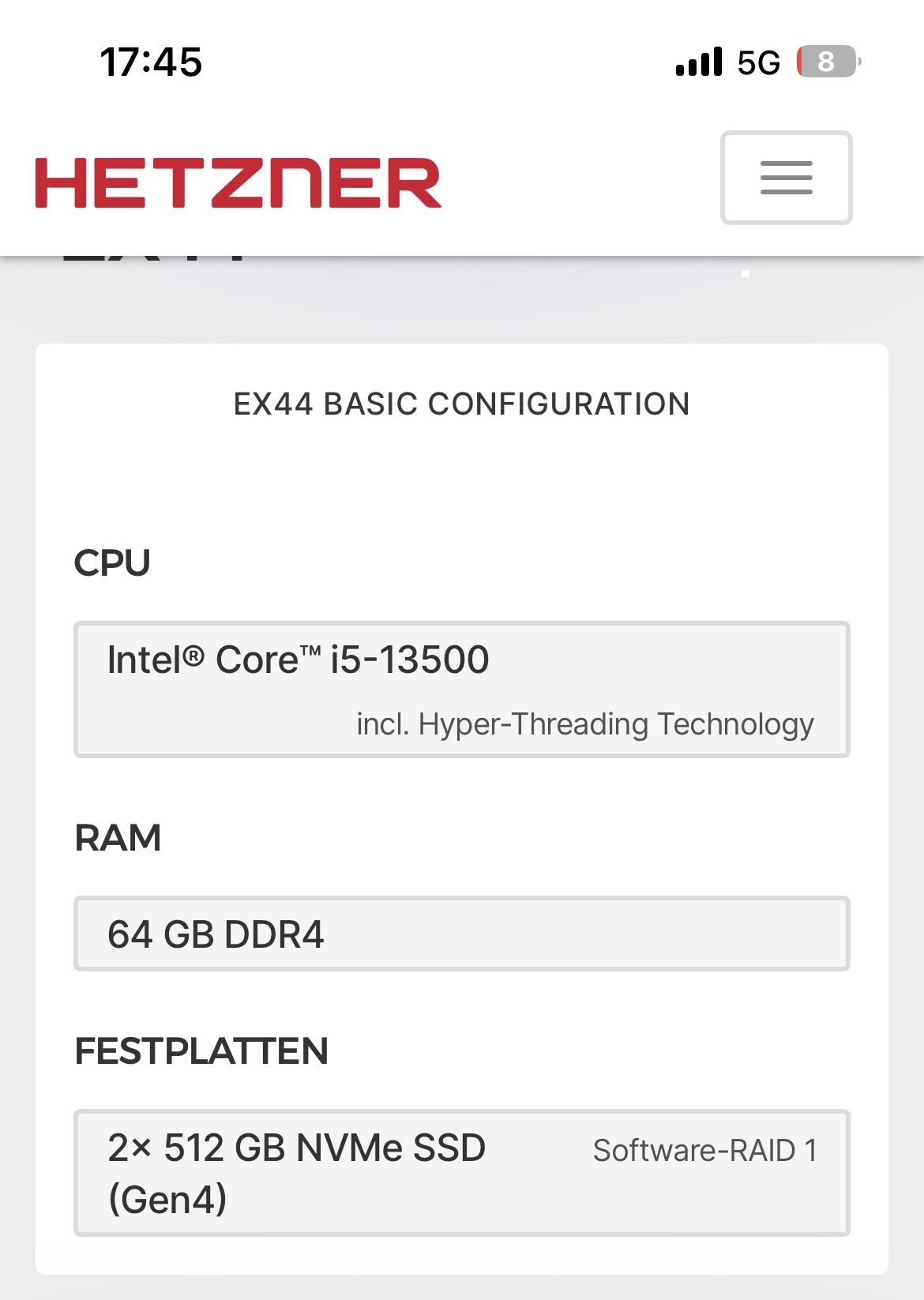

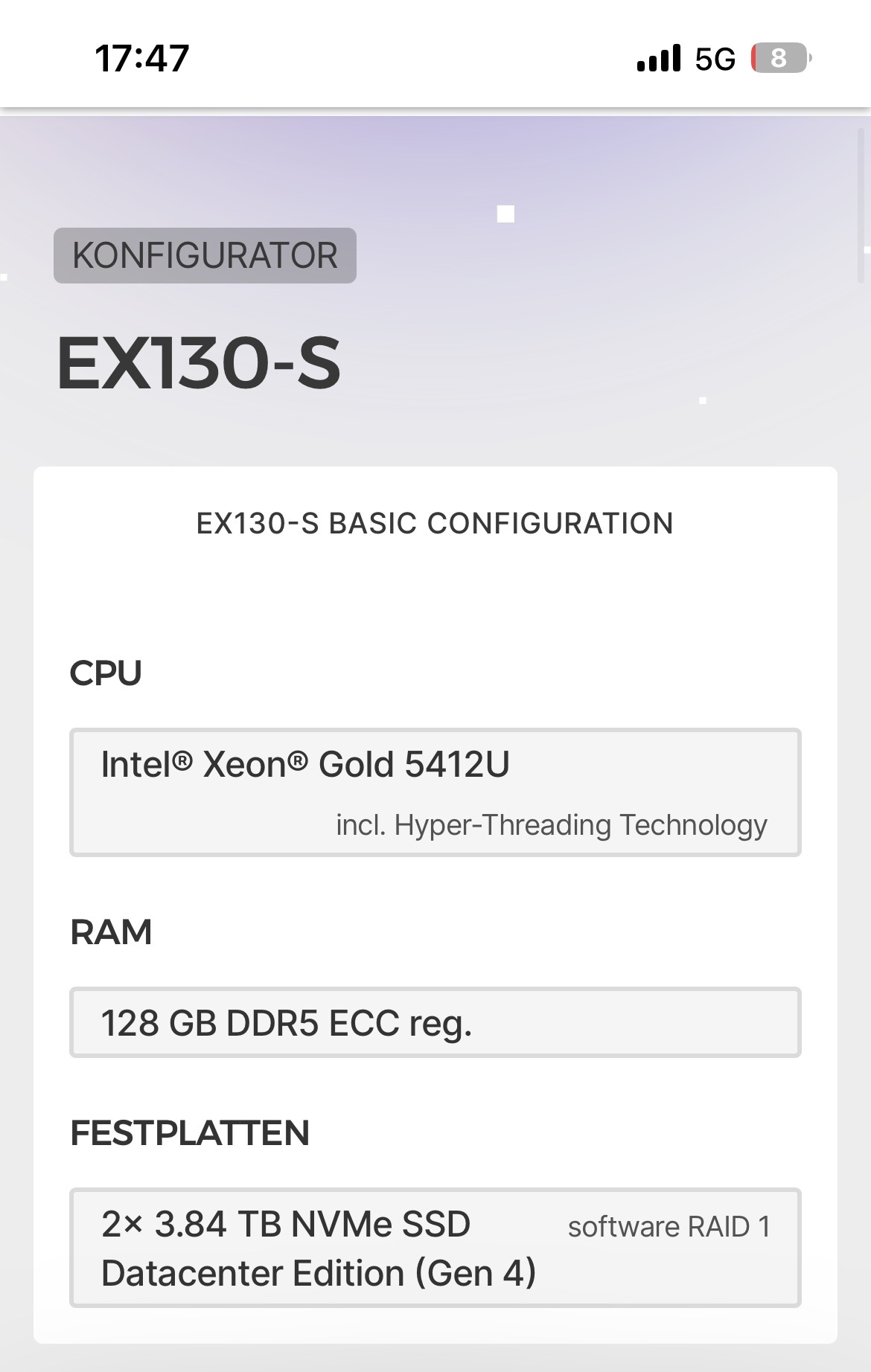
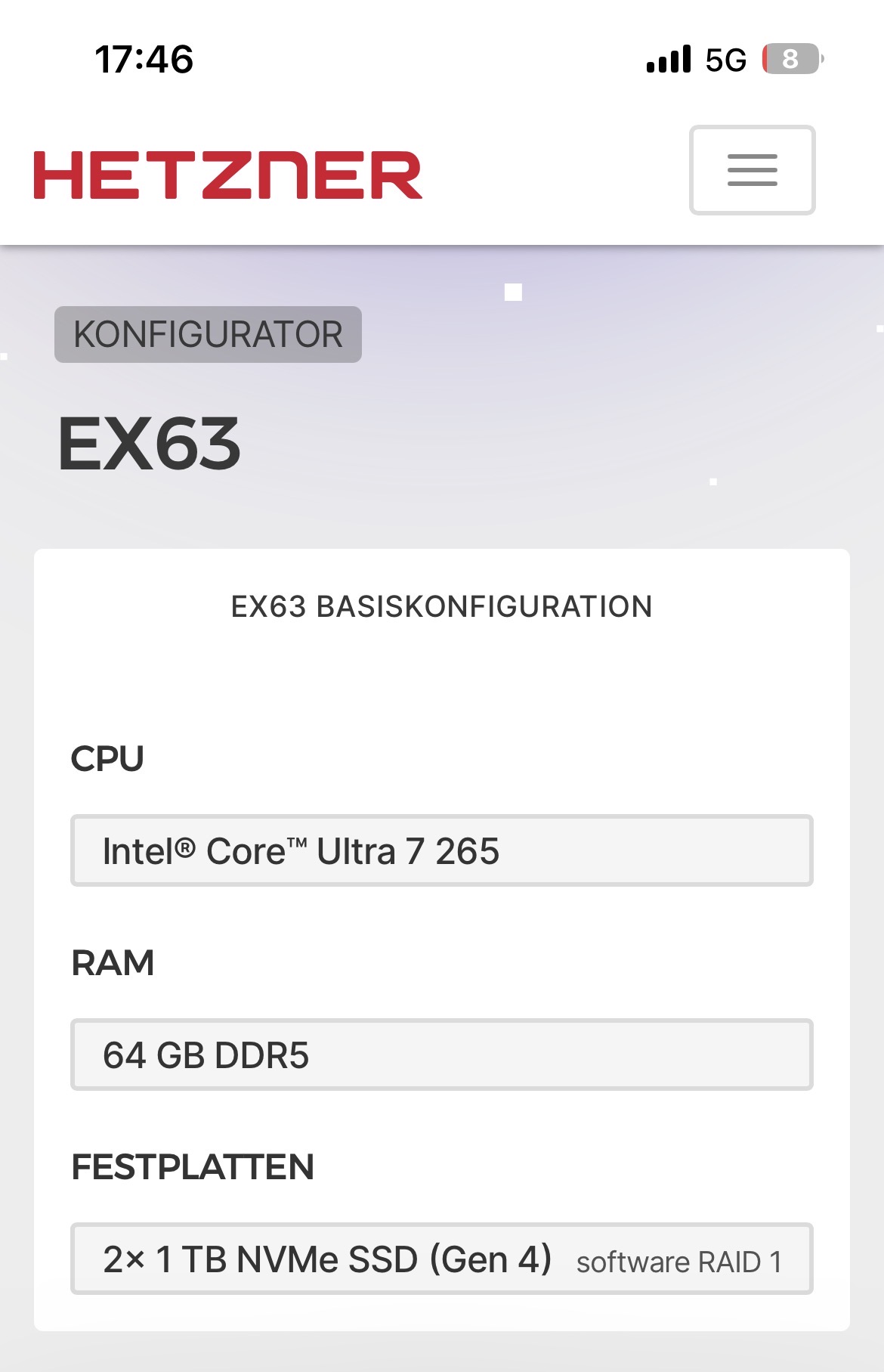
Die „Miete“ meines Kellerservers ist günstiger … Kooperieren geht da allerdings schwerer. Da bisher nur Bernd Schwendiger aktiv an den relevanten Themen mitgearbeitet hat ist der Kreis der Betroffenen aber auch relativ klein.
Hallo Hermann,
kann sicherlich auch ein Bot was machen. Ich nehme aber an, dass Wolfgang hier auch noch andere Werkzeuge in petto hat ![]()
LG Bernd